本文主要讲解关于字节携港大南大升级 LLaVA-NeXT:借 LLaMA-3 和 Qwen-1.5 脱胎换骨,轻松追平 GPT-4V相关内容,让我们来一起学习下吧!

文 | 王启隆
出品 | 《新程序员》编辑部
2023 年,威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员共同开发的 LLaVA 首次亮相,彼时它被视为一个端到端训练的大型多模态模型,展现了在视觉与语言融合领域的潜力。今年 1 月 30 日,LLaVA 的后续版本 LLaVA-NeXT 推出,它利用了当时最强的 LLM——Yi-34B,进一步增强了多模态理解、OCR(光学字符识别)和世界知识等方面的能力,甚至在一些基准测试上与 Gemini-Pro 和 GPT-V 相媲美。

在全世界默默等待 GPT-5 消息的这几个月里,开源社区出现了 LLaMA-3 和 Qwen-1.5 等语言能力更为强大的模型,阿里的 Qwen 更是在昨天发布了 2.5 版本,剑指 GPT-4。因此,LLaVA-NeXT 的研究团队开始思考一个问题:随着新型强力语言模型的诞生,开源 LLM 和私有 LLM 之间的性能差距正在缩小。当这些更强大的 LLM 被用于增强多模态模型时,是否也会促成开源多模态模型与私有多模态模型之间差距的缩小?
思来想去不如直接动手,LLaVA-NeXT 今日正式升级,研究团队直接用上了 LLaMA-3(8B)和 Qwen-1.5(72B & 110B)为 LLaVA-NeXT 提升多模态能力,最大可达模型规模的 3 倍。这使得多模态模型能够展示从 LLM 继承的更好的视觉世界知识和逻辑推理能力。
代码链接:https://github.com/LLaVA-VL/LLaVA-NeXT
此外,新版本的 LLaVA-NeXT 针对更丰富的现实场景优化视觉对话功能,满足多样应用需求。为了检验在复杂环境下的多模态能力进步,作者们搜集并开发了新评估数据集 LLaVA-Bench(Wilder),它承袭了 LLaVA-Bench (in-the-wild) 的精神,深入探究日常生活中的视觉对话,并大幅增加了数据量以进行全面评估。
开源数据集链接:https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild
为清晰体现“换了个 LLM”对多模态性能提升的贡献,本次升级沿用了 LLaVA-NeXT 的原训练方案,保持了该系列模型的简约设计和数据利用效率。最大的 1100 亿参数版本仅需在 128 台 H800 服务器上运行 18 小时即可完成训练。目前最新版 LLaVA-NeXT 的代码、数据和模型都将向公众开放。
Demo 链接:https://llava-next.lmms-lab.com/
团队成员如下,由来自南洋理工大学、香港科技大学以及字节跳动/抖音的研究人员组成。


只换语言模型,竟然就能提升多模态能力?
基准测试结果
-
SoTA 级别性能:通过简单增强 LLM 能力,LLaVA-NeXT 在各项基准测试中持续优于先前的开源多模态模型,赶上了 GPT4-V 的某些选定基准。
-
低训练成本:新版本保持了与之前 LLaVA 模型一样高效的训练策略,在与之前 LLaVA-NeXT 7B/13B/34B 模型相同的训练数据上进行了监督微调。当前最大的模型 LLaVA-NeXT-110B 在 128 台 H800-80G 上训练了 18 小时。
直接拿多模态模型去 PK SoTA 语言模型的结果
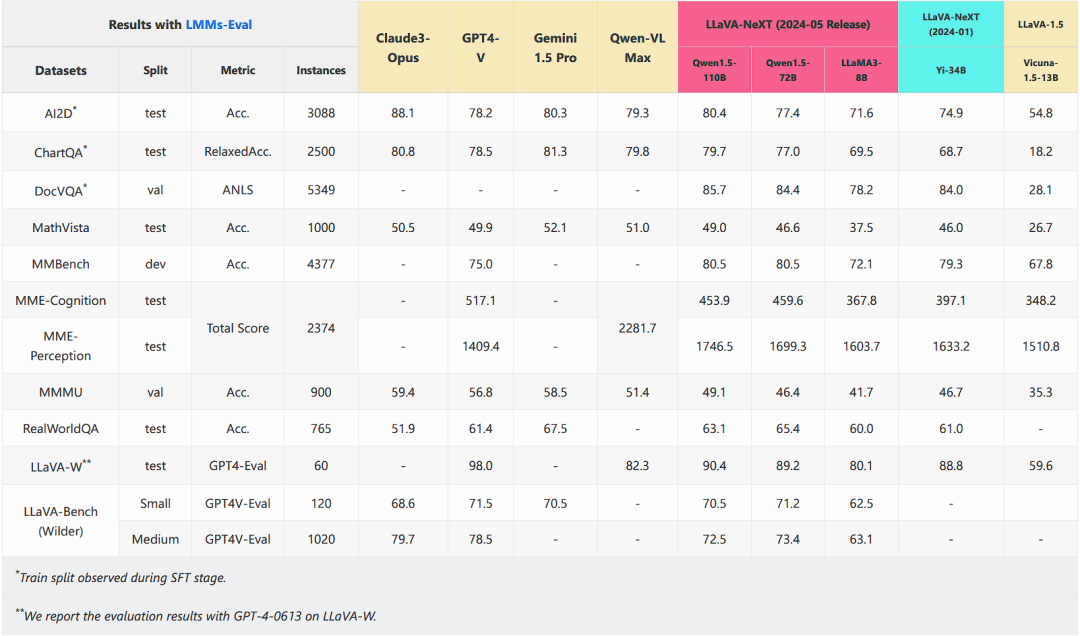
探索大语言模型的能力极限
通过 LLaVA-NeXT 的实践,研究团队见证了从 130 亿到 340 亿参数的LLM规模跃升带来的显著性能飞跃。随着更强大的开源 LLM 不断涌现,出现了新的问题:这些语言模型的能力要如何有效迁移到多模态场景?
为量化 LLM 的语言智能,研究团队参考了大规模多任务语言理解(MMLU)的评估分数。而为了检验应用相同 LLaVA-NeXT 训练方案后的多模态能力,他们参考了四组关键基准:MMMU(跨学科理解)、Mathvista(视觉数学推理)、AI2D(科学图表理解)及 LLaVA-W(日常视觉对话场景)。这些基准全面涵盖了 LMM 在实际应用中的多样化挑战。
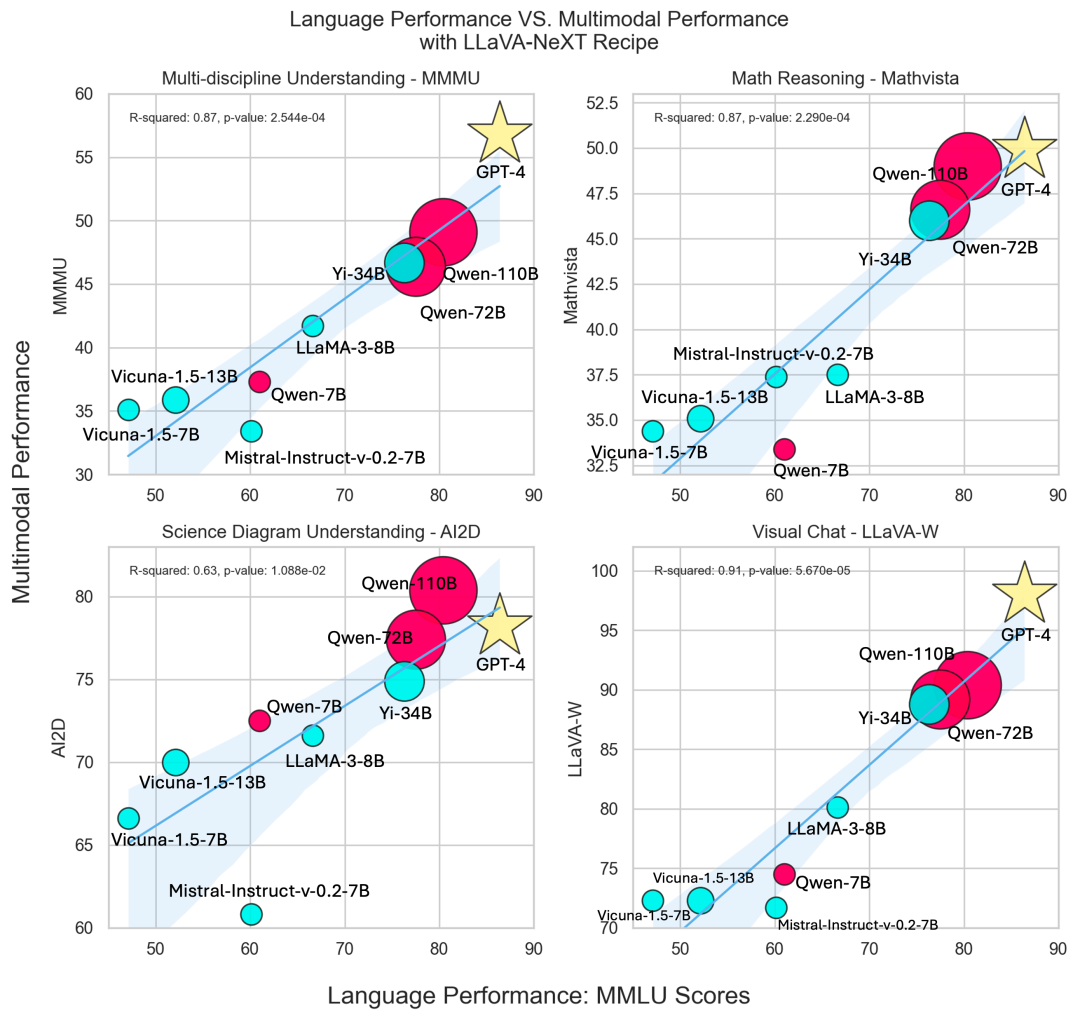
多模态与语言能力的相互促进关系在上图中以回归线形式直观展现,揭示了各基准测试的内在趋势。圆圈大小代表模型大小。
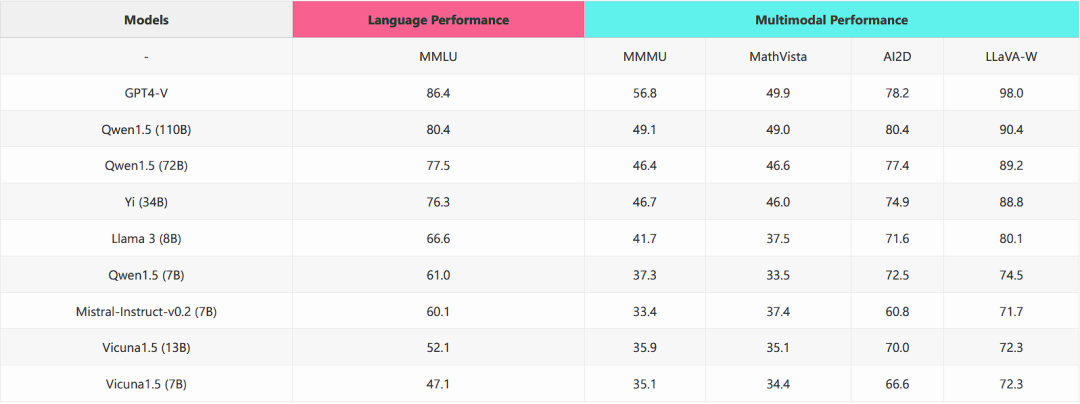
如果换成表格,那就是上图这样。

看图说话,吟诗作对
LLaVA-Bench(Wilder):日常生活视觉对话测试集
开发 LLMs 的最终目标之一是构建全能的通用助手,以帮助人类在日常生活中的各种多模态任务。因此,拥有强大的基准来精确测量相关进展至关重要。LLaVA-Bench(Wilder),也称为 LLaVA-W,正是这样一套用于评测多模态模型日常视觉对话能力的基准。
鉴于原版只有 60 个案例,研究团队意识到需要一个更为丰富的数据集。于是他们推出了 LLaVA-Bench(Wilder),分为「轻量级」120 例快速评估版和「进阶」1020 例综合测试版。这些数据集囊括了数学解题、图像解读、代码自动生成、视觉 AI 助手及基于图像的逻辑推理等多场景。数据采集自线上服务中的真实用户需求,经过严格筛选以保护隐私和减少潜在风险。所有问题的参考答案皆由 GPT4-V 生成。
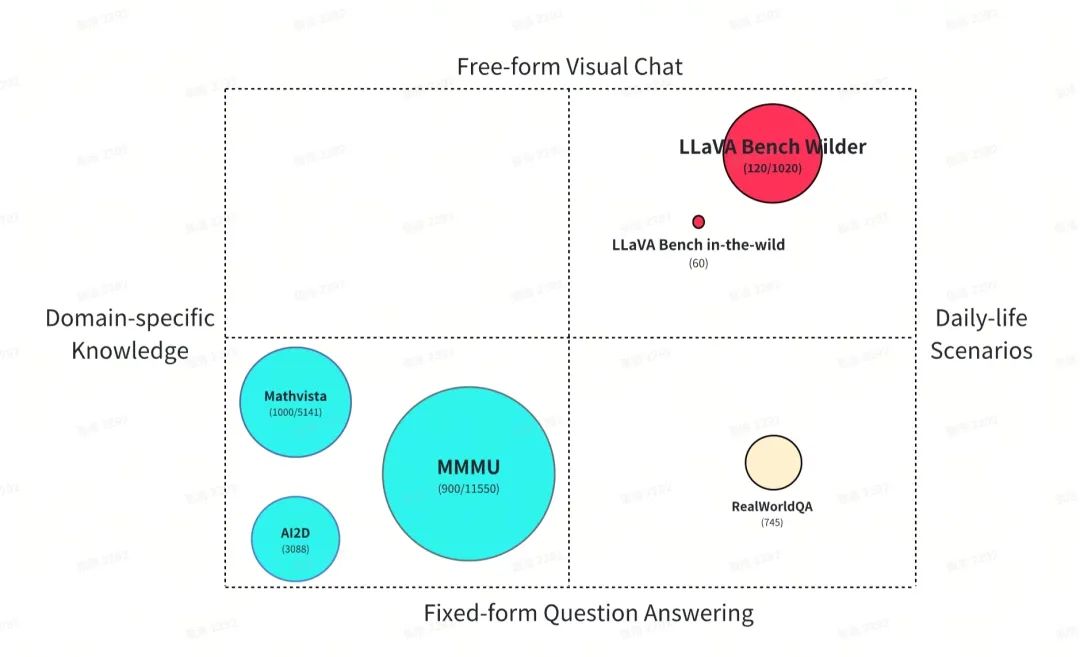
-
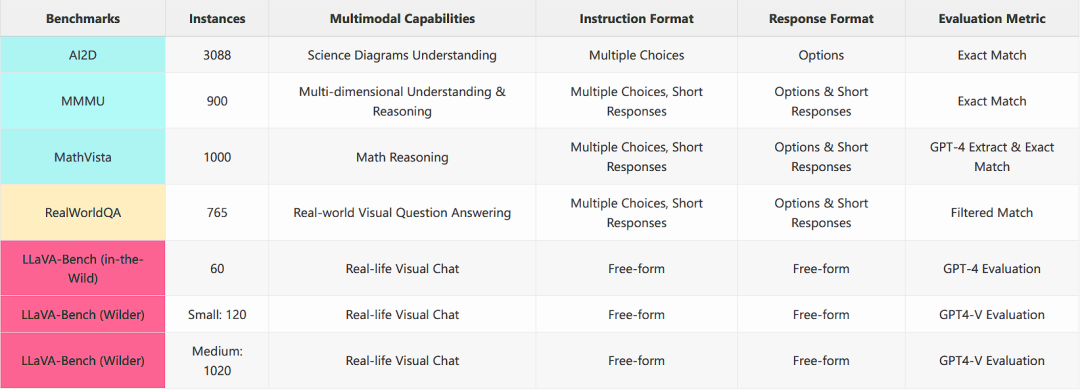
与其它基准的对比:上图展示了 LLaVA-Bench(Wider) 与其他现有的多模态模型评估基准的可视化比较。多数现有基准倾向于使用固定格式的问答(QA),便于评估和模型对比。如 MMMU、Mathvista 和 AI2D 等,专为评估多模态模型在特定知识密集型领域的表现而设。
RealWorldQA 虽聚焦日常,却限于简答形式。然而,作为助手模型,具备自由对话能力对于激发用户兴趣、突破简短问答的局限至关重要。因此,将自由形式对话融入日常生活视觉场景成为关键。LLaVA-W 开创性地提出了这一概念,而 LLaVA-Bench-Wilder 进一步扩展,引入更多生活场景和应用实例。
-
数据集构建与评价标准:对于来自在线服务的海量查询,研究团队使用 ONE-PEACE 嵌入模型生成嵌入并应用了加权 K-Means 聚类,确保高像素值图像优先被纳入测试。去重后,就形成了前文提到的 120 道「轻量级」问题和 1020 道「进阶」问题。研究团队进行了严格的去噪审核,确保数据纯净,两版重合图像比例均低于 2%,而原始 LLaVA-W 为 5%。评估数据独立于 LLaVA-NeXT 训练数据,并完成了去重处理。
-
参考答案的构建:对于每个筛选出的问题,他们首先使用 GPT-4V 生成参考响应,并邀请人工注释者手动验证问题和参考答案的准确性。面对含糊不清、涉及图片分辨率或无关图片内容的询问,GPT4-V 可能拒绝回应或给出错误答案。所以为了维护数据质量只能人工复核并修订了这些问题,确保信息的准确与可信。
-
评分机制:采用了与 LLaVA-W 相同的评估流程,但用 GPT4-V 替换了 GPT-4。研究团队没有采用多分类评分,而是直接比较 GPT4-V 参考答案与模型回答的匹配度。实践中,他们发现这种评分方式未能充分暴露模型间差异,有时不公正地降低了参考答案得分,导致模型缺陷未能在总分中充分体现。为此,他们设定 GPT4-V 对正确答案一律打满分,确保其他模型因错误而承受更高扣分,从而更精确地评估模型在实际情境中的表现力。
再来 PK 一次!
-
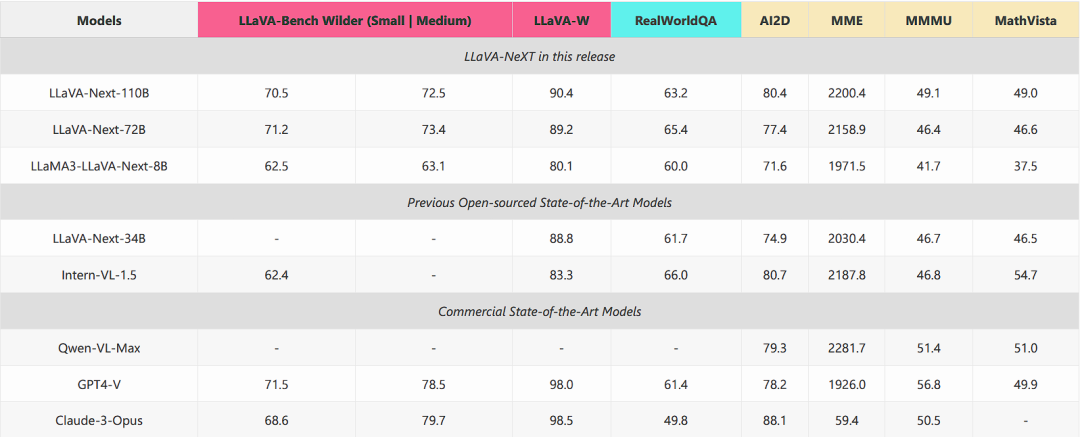
量化结果:与其他基准测试相比,LLaVA-Bench(Wilder)提供的独特测量结果非常明显,因为最先进的(SoTA)LMM 之间存在巨大的性能差距。正如 LLaVA-Bench (Wilder) 所评估的那样,某些在知识密集型任务中表现出色的 LMM 在日常生活的可视聊天场景中可能并不出色。最新版本中的 LLaVA-NeXT 模型在各个领域的性能都有所提高。

参数信息
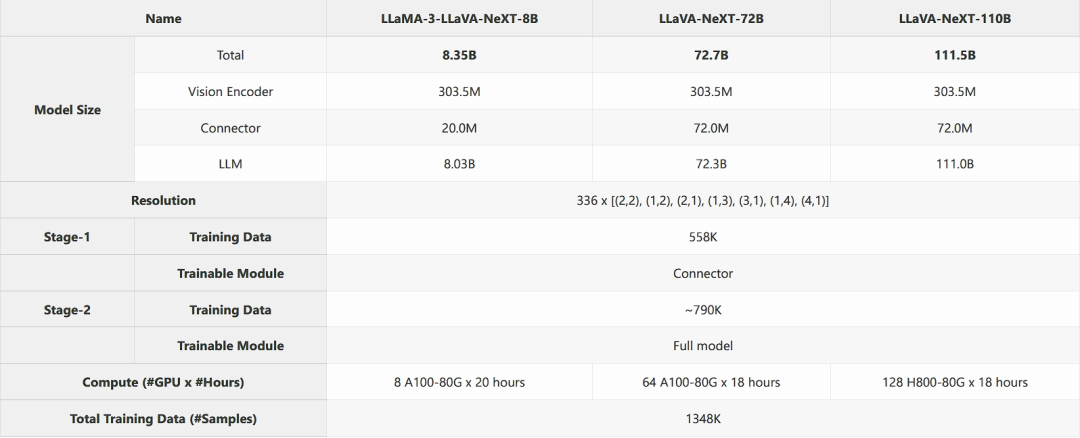
模型型号:LLaMA-3-LLaVA-NeXT-8B、LLaVA-NeXT-72B 和 LLaVA-NeXT-110B。
模型架构:
-
视觉编码器部分的参数量为 303.5M。
-
连接器部分的参数量分别为 20.0M(LLaMA-3-LLaVA-NeXT-8B)、72.0M(LLaVA-NeXT-72B)和 72.0M(LLaVA-NeXT-110B)。
-
大规模语言模型(LLLM)部分的参数量分别为 8.03B(LLaMA-3-LLaVA-NeXT-8B)、738.3B(LLaVA-NeXT-72B)和 111.0B(LLaVA-NeXT-110B)。
分辨率列显示了图像输入的尺寸:336 x [(2), (1,2), (2,1), (1,3), (3,1), (1,4), (4,1)]。
训练数据部分展示了两个阶段的数据集大小:
-
第一阶段的训练数据为 558K 样本。
-
第二阶段的训练数据约为 790K 样本。
训练模块部分表明第一阶段只训练连接器,而第二阶段则训练整个模型。
计算资源部分说明了每个模型所需的 GPU 数量和训练时间:
-
LLaMA-3-LLaVA-NeXT-8B 使用 8 个 A100-80G GPU,训练时间为 20 小时。
-
LLaVA-NeXT-72B 使用 64 个 A100-80G GPU,训练时间为 18 小时。
-
LLaVA-NeXT-110B 使用 128 个 H800-80G GPU,训练时间为 18 小时。
最后,总训练数据量为 1348K 样本。
参考资料:
https://llava-vl.github.io/blog/2024-05-10-llava-next-stronger-llms/


以上就是关于字节携港大南大升级 LLaVA-NeXT:借 LLaMA-3 和 Qwen-1.5 脱胎换骨,轻松追平 GPT-4V相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!
转载请注明:字节携港大南大升级 LLaVA-NeXT:借 LLaMA-3 和 Qwen-1.5 脱胎换骨,轻松追平 GPT-4V | 程序员导航网












