本文主要讲解关于使用XxlCrawler抓取全球航空公司ICAO三字码相关内容,让我们来一起学习下吧!
目录
前言
一、数据源介绍
1、目标网站
2、页面渲染结构
二、XxlCrawler信息获取
1、创建XxlCrawler对象
2、定义PageVo对象
3、直接PageVO解析
4、自定义解析
总结
前言
长距离旅行或者出差,飞机一定是出行的必备方式。对于旅行达人或者出差人员而言,登机牌也是随身之物。还记得我第一次坐飞机出行的时候,相当激动,第一次在飞机上看祖国的大好河山,有一种豪迈的既视感。有点扯远了,不知道大家出行的时候有没有认真的研究一下登机牌。登机牌上都有什么信息呢。这里从网上贴一张别人的登机牌,我们来看一下。

在上面这张机票包含了一些重要的信息,以大木航为例,承运人:MU,航班:MU。这个MU表示的是什么呢?MU是航空公司的二字码,官方名字IATA,国际航空运输协会 (International Air Transport Association,IATA) 是一个由世界各国航空公司所组成的大型国际组织,其前身是1919年在海牙成立并在二战时解体的国际航空业务协会。MU是这个协会给中国东方航空的一个唯一身份码。
就像我们的身份证一样,与IATA码有一点区别的是ICAO码。相对于IATA码,ICAO一般老百姓接触的比较少。因为ICAO是国际民航组织(International Civil Aviation Organization,缩写为ICAO,是协调世界各国政府在民用航空领域内各种经济和法律事务、制定航空技术国际标准的重要组织。ICAO主要用于安全保卫或空防安全活动,实施国际民航组织通信、导航、监视/空中交通管制系统,简化手续、统计、技术合作、培训等。简单一点说,就是航空管控、导航方面,一般通用的是ICAO码。而MU对应的ICAO码是CES。这个信息可以从东航官网上可以查到。

那么全球有哪些航空公司,他们的ICAO码又是什么呢?本文通过从航班追踪网站flightaware,获取实时的航班对应的航空公司信息。本文介绍一种基于XxlCrawler的信息抓取技术,自动从网站上获取全球的航空公司信息,同时分享两种不同的数据解析方式,最后将获取的信息保存为Excel,通过本文不仅可以获取ICAO的数据,同时掌握两种数据解决方法。如果您当前对数据处理有需求,可以看看本文是否有帮助。
一、数据源介绍
当然,想获取ICAO数据不一定要从飞行跟踪网站上获取,这里只提供一种数据源。某度和某哥都可以拿到完整的ICAO数据。本节将对飞行网站上的数据进行简单说明,为下一步我们来进行数据抓取奠定基础。
1、目标网站
在个人浏览器中打开目标网站的地址,查看实时航班。然后点击航空公司列表,可以看到下面的页面:

在上面的页面中其实就包含了我们需要的航空公司ICAO码,以及对应航空公司的英文名称。比如CES China Eastern "China Eastern" (China) 就表示中国东方航空。
2、页面渲染结构
在获取了网站展示页面之后,我们可以来看看具体的数据,打开网页的调试功能,可以看到如下的信息:

请注意图中红色框标记的地方,从最顶层的pageContainer,到下级prettyTable,然后是表格中的tbody再到tr,最后是td没一行。通过遍历td即是我们需要的数据。因此我们要解析的就是获取tr的集合,然后遍历下面的td,第一个td的文本值是航班数,第二个就是ICAO代码,第三个是航空公司的英文名称。
上面的知识一定要了解,这是下面章节的前提条件。
二、XxlCrawler信息获取
在了解了信息渲染的对象和网页层次之后,我们就可以采用熟悉的XxlCrawler来进行全球航空公司列表及ICAO代码获取实战。本节主要讲述如何进行代码开发,同时讲述两种页面解析模式,实际生产中,可以按照自己的需要进行灵活处理。
1、创建XxlCrawler对象
在进行信息抓取前,需要定义抓取对象,这里分享其代码:
private static final String GET_ICAO_URL = "https://zh.flightaware.com/live/fleet/";
private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36";// 构造爬虫
XxlCrawler crawler = new XxlCrawler.Builder()
.setUrls(GET_ICAO_URL)
// 允许扩散爬取,将会以现有URL为起点扩散爬取整站,这里爬一个页面,不允许扩散
.setAllowSpread(false)
.setThreadCount(3)
.setPauseMillis(2000)
.setUserAgent(USER_AGENT)//设置user_agent
.setIfPost(false)
.setFailRetryCount(3)// 重试三次
.setPageParser(new PageParser<PageVo>() {
@Override
public void parse(Document html, Element pageVoElement, PageVo pageVo) {
// 解析封装 PageVo 对象
// String pageUrl = html.baseUri();
//第一种方式:使用自助解析,实现更加灵活的模式
// printElementVo(pageVoElement);
//第二种方式:使用pageVO的方式解析
printVo(pageVo);
// System.out.println(pageUrl + ":" + pageVo.toString());
}
}).build();需要说明的是,这里只需要对目标页面爬取一次,因此不需要进行扩散抓起,否则速度会很慢,相当于自我发现地址,同时还要实现抓取。这里通过.setAllowSpread(false) 就可以防止这种操作。
2、定义PageVo对象
pageVo对象用于网页数据的解析,这里我们可以将数据过滤到tbody,然后剩下的解析到属性中,这是一种防范,另一种方法是通过自定义解析。不管用那种解析,都需要对数据进行第一次解析,也就是pageVO的定义。下面来看一下PageVo对象怎么定义:
@PageSelect(cssQuery = ".pageContainer .prettyTable >tbody")
@Data
public static class PageVo {
/**
* 实时航班数
*/
@PageFieldSelect(cssQuery = ">tr >td:eq(0)")
private List<String> flightsNum;
/**
* ICAO代号
*/
@PageFieldSelect(cssQuery = ">tr >td:eq(1)")
private List<String> icaoCode;
/**
* 航空公司(英文)
*/
@PageFieldSelect(cssQuery = ">tr >td:eq(2)")
private List<String> airline;
}这里为了解析方便,同时在解析时,自动创建三个数组,分别用来保存第一个到最后一个td中的值。前文提过,三个值分别代表航班数、icao代码、航空公司英文名称。使用这种直接解析成数组的方式呢,优缺点都有。优点就是不需要再进行第二次解析,缺点就是,如果有多个td就得定义多个数组去接收,比较繁琐。这里暂时不提自定义解析,先把这种固定模板的解析模式讲解完。
3、直接PageVO解析
通过定义PageVO对象,同时给VO对象配置@PageFieldSelect(cssQuery = ">tr >td:eq(1)"),就可以实现属性的自助解析。这里新增一个方法,把解析之后的数据打印输出,方便观察调试结果。
protected void printVo(PageVo pageVo) {
System.out.println(pageVo);
System.out.println(pageVo.getFlightsNum().size());
System.out.println(pageVo.getFlightsNum());
System.out.println(pageVo.getAirline().size());
System.out.println(pageVo.getAirline());
System.out.println(pageVo.getIcaoCode().size());
System.out.println(pageVo.getIcaoCode());
for (int i = 0; i < pageVo.getFlightsNum().size(); i++) {
System.out.println("航班数:" + pageVo.getFlightsNum().get(i) + "t ICAO代码:" + pageVo.getIcaoCode().get(i)
+ "t 航空英文名称:" + pageVo.getAirline().get(i));
}
}运行以上代码可以看到以下结果:

通过观察控制台输出可以看到,相关信息已经被成功爬取了。
4、自定义解析
如果要解析的网页信息量不是很大,以表格为例,其单元格也不是很多,可以使用上面的这种注解式的解析模式,但是如果单元格比较多,我们在pageVo中需要定义多个list,这样也是比较麻烦的。这里分享一种自定义解析模式,自己根据xpath去解析网页,获取数据。
与注解解析模式原理差不多,自定义解析是根据网页的变化,自动根据网页结构解析内容,保存到相关集合中。
protected void printElementVo(Element pageVoElement) {
System.out.println(pageVoElement);
System.out.println(pageVoElement.childrenSize());
List<AirlineVo> airlineList = new ArrayList<TestZhFlightawareCase.AirlineVo>();
for (int i = 0; i < pageVoElement.childrenSize(); i++) {
Element childElement = pageVoElement.child(i);
// System.out.println(childElement.childrenSize());
int childrenSize = childElement.childrenSize();
System.out.println(childrenSize);
String flightsNum = childElement.child(0).text();
String icao = childElement.child(1).text();
String airline = childElement.child(2).text();
System.out.println("航班数:" + flightsNum + "t ICAO代码:" + icao + "t 航空英文名称:" + airline);
airlineList.add(new AirlineVo(flightsNum, icao, airline));
}
// excel工具包
ExcelUtil<AirlineVo> util = new ExcelUtil<AirlineVo>(AirlineVo.class);
util.exportExcel(airlineList, "全球航空公司ICAO代码表-20240514");
}@Data
@AllArgsConstructor
@NoArgsConstructor
public class AirlineVo {
@Excel(name = "航班数")
private String flightsNum;
@Excel(name = "icao代码")
private String icaoCode;
@Excel(name = "航空公司英文名称")
private String airlineEn;
}代码的最后,我们实现了将抓取的信息列表保存到excel表格中。当然,您也可以根据需要,把数据保存到业务数据库中,这里暂且不表。

在数据解析之前,可以先拿到抓取的tbody信息,然后再来解析到具体的数据存储对象中。最后是解析的数据打印信息:
航班数:413 ICAO代码:AAL 航空英文名称:American Airlines "American"
航班数:409 ICAO代码:DAL 航空英文名称:Delta "Delta"
航班数:387 ICAO代码:UAL 航空英文名称:United "United"
航班数:309 ICAO代码:SWA 航空英文名称:Southwest "Southwest" (Dallas, TX)
航班数:290 ICAO代码:CSN 航空英文名称:China Southern Airlines "China Southern" (China)
航班数:272 ICAO代码:RYR 航空英文名称:Ryanair "Ryanair" (Ireland)
航班数:236 ICAO代码:CES 航空英文名称:China Eastern "China Eastern" (China)
航班数:213 ICAO代码:CCA 航空英文名称:Air China "Air China" (China)
航班数:156 ICAO代码:IGO 航空英文名称:IndiGO "IFLY" (New Delhi)最后到工程文件中看一下是否成功生成了excel文件,在工程目录下有一个download目录,在这个目录中可以看到已经生成了对应的excel文件。

打开Excel看看是不是我们想要的数据,
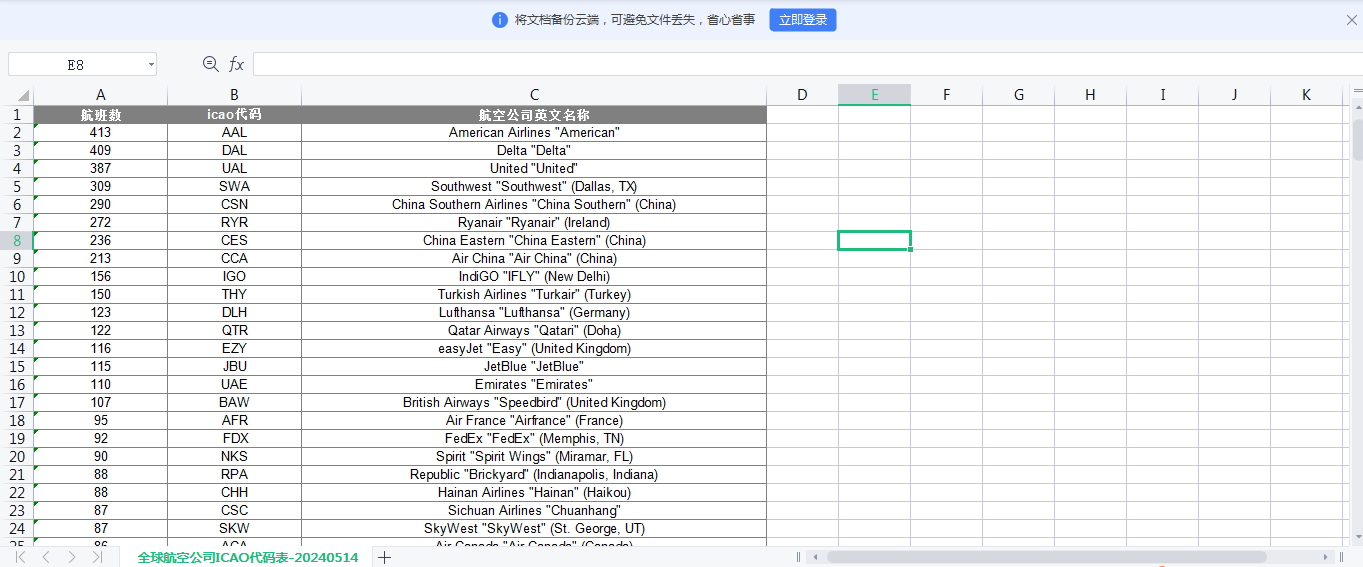
通过上图可以看到,与我们的预期是一致的,已经成功的全球航空公司的名称、航班数、ICAO代码都保存到了Excel中。
总结
以上就是本文的主要内容,本文介绍一种基于XxlCrawler的信息抓取技术,自动从网站上获取全球的航空公司信息,同时分享两种不同的数据解析方式,最后将获取的信息保存为Excel,通过本文不仅可以获取ICAO的数据,同时掌握两种数据解决方法。如果您当前对数据处理有需求,可以看看本文是否有帮助。全球航空公司ICAO数据可以在评论区留言获取哦。以后有机会可以把航空公司跟国家等关联起来,就可以知道哪个是航空大国。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,万分感谢。
以上就是关于使用XxlCrawler抓取全球航空公司ICAO三字码相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!












