本文主要讲解关于AI大模型探索之路-实战篇3:基于私有模型GLM-企业级知识库开发实战相关内容,让我们来一起学习下吧!
文章目录
- 前言
- 概述
- 一、本地知识库核心架构回顾(RAG)
-
- 1. 知识数据向量化
- 2. 知识数据检索返回
- 二、大模型选择
-
- 1. 模型选择标准
- 2. ChatGLM3-6B
- 三、Embedding模型选择
- 四、改造后的技术选型
- 五、资源准备
-
- 1. 安装git-lfs
- 2. 下载GLM模型
- 3. 下载Embeding模型
- 六、代码落地实践
-
- 1. Embedding代码改造
- 2. LLM代码改造
- 3. 测试运行
- 总结
前言
在当今信息时代,数据已经成为企业的核心资产之一。对于许多企业而言,信息安全和私密性是至关重要的,因此对外部服务提供的数据接口存在天然的警惕性。因此常规的基于在线大模型接口落地企业知识库项目,很难满足这些企业的安全需求。面对这样的挑战,只有私有化的部署方案才能满足企业需求;
在实战篇2中《AI大模型探索之路-实战篇2:基于CVP架构-企业级知识库实战落地》,设计实现了基于CVP架构的企业知识库。本篇文章中将对企业知识库进行进一步的改造升级,以满足企业安全性方面的需求;利用开源的GLM大模型,进行私有化部署,重新设计落地整个企业级知识库。
概述
在构建企业知识库的过程中,通常会涉及两种类型的大模型API:嵌入向量化模型和LLM语言分析处理模型。为了确保企业的安全性需求得到满足,我们采用开源的GLM大模型进行私有化部署,并重新设计了整个知识库机器人的架构。接下来,我们将深入探讨这一改造升级过程。
一、本地知识库核心架构回顾(RAG)
1. 知识数据向量化
首先,通过文档加载器加载本地知识库数据,然后使用文本拆分器将大型文档拆分为较小的块,便于后续处理。接着,对拆分的数据块进行Embedding向量化处理,最后将向量化后的数据存储到向量数据库中以便于检索。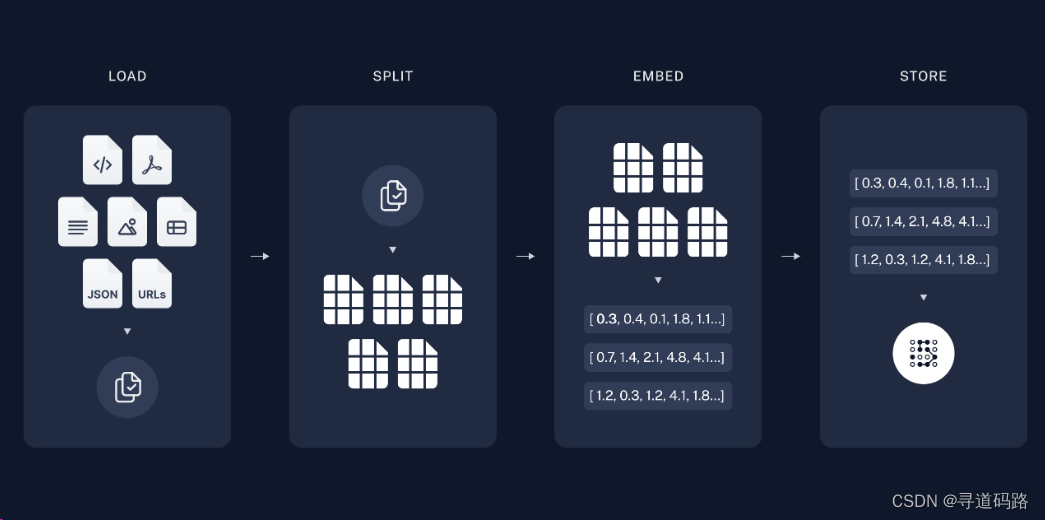
2. 知识数据检索返回
根据用户输入,使用检索器从向量数据库中检索相关的数据块。然后,利用包含问题和检索到的数据的提示,交给ChatModel / LLM(聊天模型/语言生成模型)生成答案。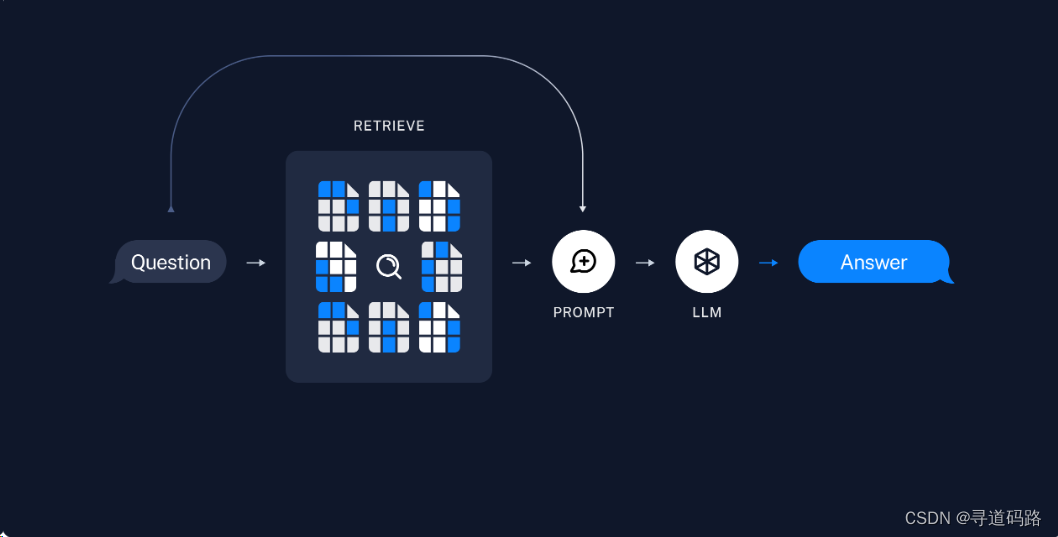
二、大模型选择
1. 模型选择标准
1)开源的:需要选择开源的项目方便自主扩展。 2)高性能的:选择各方面性能指标比较好的,能够提升用户体验。 3)可商用的:在不增加额外成本的前提下,保证模型的商用可行性。 4)低成本部署的:部署时要能够以最低成本代价部署运行知识库,降低公司成本开支。 5)中文支持:需要选择对我母语中文支持性比较好的模型,能够更好的解析理解中文语义。
2. ChatGLM3-6B
ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,也是目前各方面性能比较突出的大模型: 1)更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。 2)更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。 3)更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。
三、Embedding模型选择
我们要选择一个开源免费的、中文支持性比较好的,场景合适的,各方面排名靠前的嵌入模型。MTEB排行榜是衡量文本嵌入模型在各种嵌入任务上性能的重要基准;可从排行榜中选相应的Enbedding模型;
本次从中选择使用比较广泛的 bge-large-zh-v1.5 (同样也是智谱AI的开源模型)
四、改造后的技术选型
1)LLM模型:ChatGLM3-6B 2)Embedding模型:bge-large-zh-v1.5 3)应用开发框架:LangChain 4)向量数据库:FAISS/pinecone/Milvus 5)WEB框架:streamlit/gradio
五、资源准备
将 Hugging Face Hub 上的预训练模型,下载到本地使用更方便,性能更快。
1. 安装git-lfs
1)需要先安装Git LFS ,Ubuntu系统操作命令:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
Centos命令参考:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
sudo yum install git-lfs
2)执行:git lfs install

2. 下载GLM模型
下载使用huggingface上的大模型
git clone https://huggingface.co/THUDM/chatglm3-6b
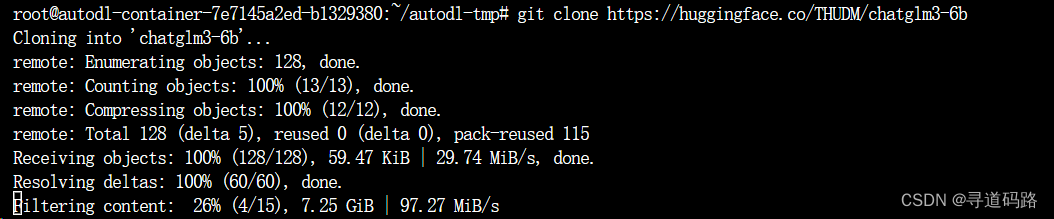
注意:下载后记得和huggingface上的文件列表对比,看看是否有缺失,缺少了单独下载补全。
3. 下载Embeding模型
下载huggingface上的词嵌入模型
git clone https://huggingface.co/BAAI/bge-large-zh-v1.5

注意:下载后记得和huggingface上的文件列表对比,看看是否有缺失,缺少了单独下载补全。
对比后发现果然少了pytorch_model.bin文件
手动单独下载pytorch_model.bin文件
wget https://huggingface.co/BAAI/bge-large-zh-v1.5/resolve/main/pytorch_model.bin
结果下载超时了???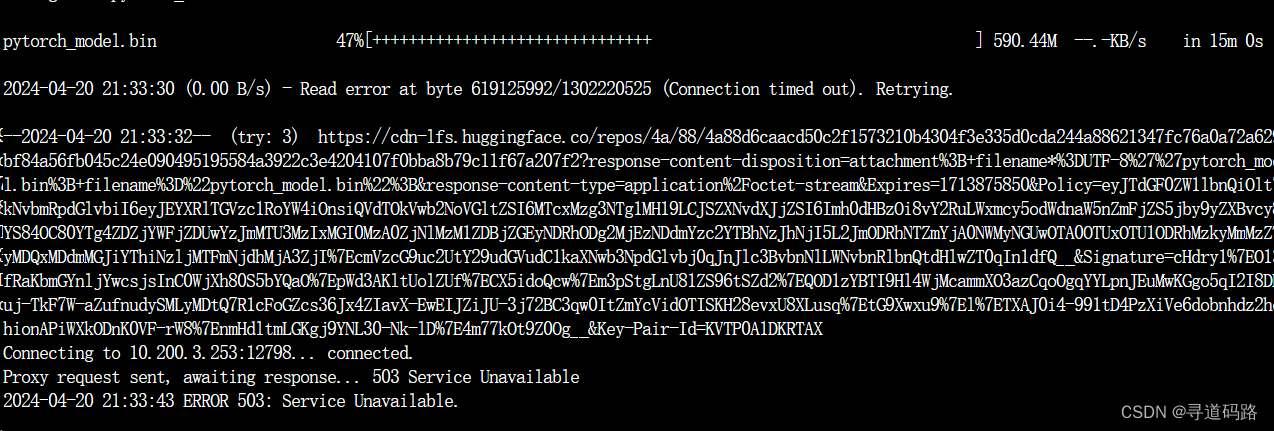
后发现国内gitee上有一个hf-models; 专门放的hugginface的模型。?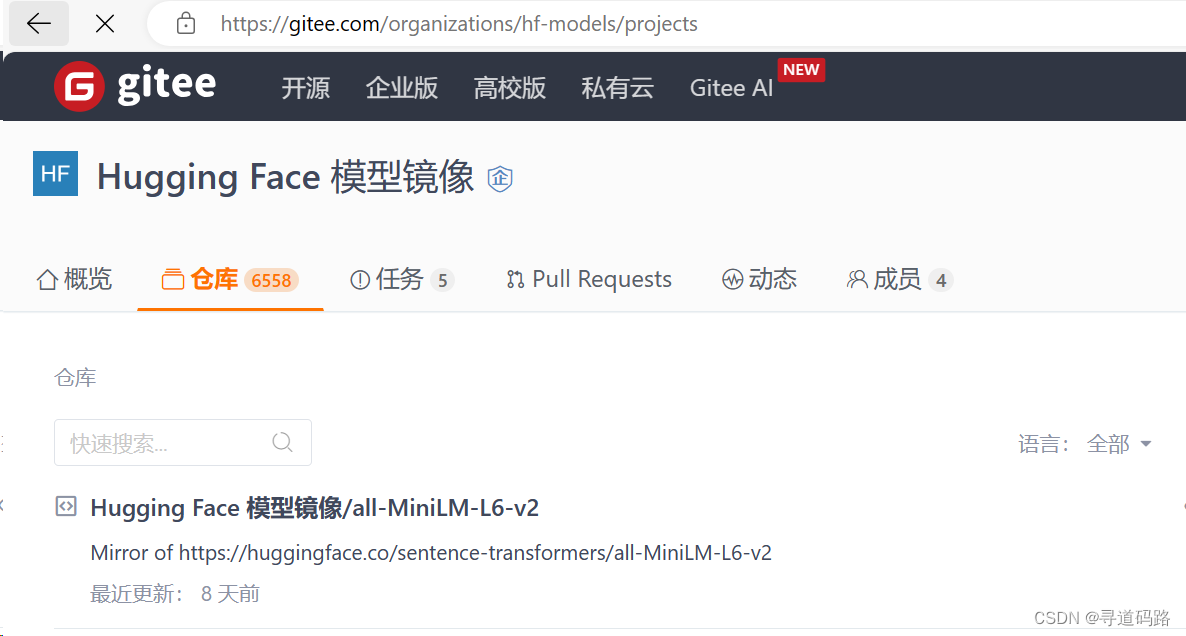
改用gitee地址下载
git clone https://gitee.com/hf-models/bge-large-zh-v1.5.git
果然皇天不负苦心人。。。。?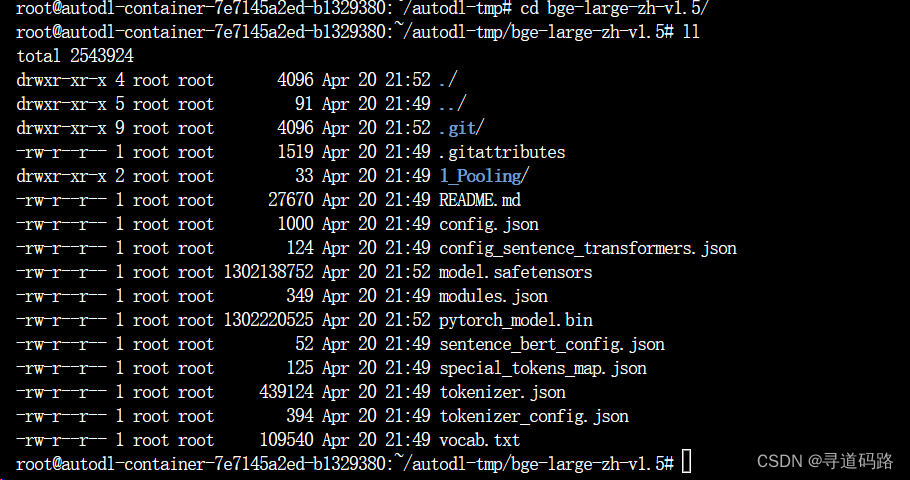
六、代码落地实践
1. Embedding代码改造
将原来的openai嵌入模型
def get_openaiEmbedding_model():
return OpenAIEmbeddings(openai_api_key=Keys.OPENAI_API_KEY,
openai_api_base=Keys.OPENAI_API_BASE)
改造替换为私有嵌入模型:
# 私有嵌入模型部署
embedding_model_dict = {
#"text2vec3": "shibing624/text2vec-base-chinese",
#"baaibge": "BAAI/bge-large-zh-v1.5",
#"text2vec3": "/root/autodl-tmp/text2vec-base-chinese",
"baaibge": "/root/autodl-tmp/bge-large-zh-v1.5",
}
def get_embedding_model(model_name="baaibge"):
"""
加载embedding模型
:param model_name:
:return:
"""
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
print(embedding_model_dict[model_name])
return HuggingFaceEmbeddings(
model_name=embedding_model_dict[model_name],
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
2. LLM代码改造
将原来的OpenAI的LLM模型
def get_openai_model():
llm_model = ChatOpenAI(openai_api_key=Keys.OPENAI_API_KEY,
model_name=Keys.MODEL_NAME,
openai_api_base=Keys.OPENAI_API_BASE,
temperature=0)
return llm_model
改造为GLM的LLM模型
def get_chatglm3_6b_model(model_path=keys.Keys.CHATGLM3_MODEL_PATH):
MODEL_PATH = os.environ.get('MODEL_PATH', model_path)
llm = chatglm3()
llm.load_model(model_name_or_path=MODEL_PATH)
return llm
chatglm3说明:由于langchain中暂未集成ChatGLM,因此需要自己封装一个ChatGLM的类
import json
from langchain.llms.base import LLM
from transformers import AutoTokenizer, AutoModel, AutoConfig
from typing import List, Optional
import os,yaml
from models.utils import tool_config_from_file
class chatglm3(LLM):
max_token: int = 8192
do_sample: bool = False
#do_sample: bool = True
temperature: float = 0.8
top_p = 0.8
tokenizer: object = None
model: object = None
history: List = []
tool_names: List = []
has_search: bool = False
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "ChatGLM3"
def load_model(self, model_name_or_path=None):
model_config = AutoConfig.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
self.tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
self.model = AutoModel.from_pretrained(
model_name_or_path, config=model_config, trust_remote_code=True
).half().cuda()
# def tool_config_from_file(tool_name, directory="../Tool/"):
# """search tool yaml and return json format"""
# for filename in os.listdir(directory):
# if filename.endswith('.yaml') and tool_name in filename:
# file_path = os.path.join(directory, filename)
# with open(file_path, encoding='utf-8') as f:
# return yaml.safe_load(f)
# return None
def _tool_history(self, prompt: str):
ans = []
tool_prompts = prompt.split(
"You have access to the following tools:nn")[0].split("nnUse a json blob")[0].split("n")
tool_names = [tool.split(":")[0] for tool in tool_prompts]
self.tool_names = tool_names
tools_json = []
for i, tool in enumerate(tool_names):
tool_config = tool_config_from_file(tool)
if tool_config:
tools_json.append(tool_config)
else:
ValueError(
f"Tool {tool} config not found! It's description is {tool_prompts[i]}"
)
ans.append({
"role": "system",
"content": "Answer the following questions as best as you can. You have access to the following tools:",
"tools": tools_json
})
query = f"""{prompt.split("Human: ")[-1].strip()}"""
return ans, query
def _extract_observation(self, prompt: str):
return_json = prompt.split("Observation: ")[-1].split("nThought:")[0]
self.history.append({
"role": "observation",
"content": return_json
})
return
def _extract_tool(self):
if len(self.history[-1]["metadata"]) > 0:
metadata = self.history[-1]["metadata"]
content = self.history[-1]["content"]
if "tool_call" in content:
for tool in self.tool_names:
if tool in metadata:
input_para = content.split("='")[-1].split("'")[0]
action_json = {
"action": tool,
"action_input": input_para
}
self.has_search = True
return f"""Action: ```{json.dumps(action_json, ensure_ascii=False)}
```"""
final_answer_json = {
"action": "Final Answer",
"action_input": self.history[-1]["content"]
}
self.has_search = False
return f"""Action: ```{json.dumps(final_answer_json, ensure_ascii=False)}```"""
def _call(self, prompt: str, history: List = [], stop: Optional[List[str]] = ["<|user|>"]):
print("======")
print(prompt)
print("======")
if not self.has_search:
self.history, query = self._tool_history(prompt)
else:
self._extract_observation(prompt)
query = ""
# print("======")
# print(history)
# print("======")
_, self.history = self.model.chat(
self.tokenizer,
query,
history=self.history,
do_sample=self.do_sample,
max_length=self.max_token,
temperature=self.temperature,
)
response = self._extract_tool()
history.append((prompt, response))
return response
3. 测试运行
在knowledge_base_v2 下运行:streamlit run knowledge_chatbot.py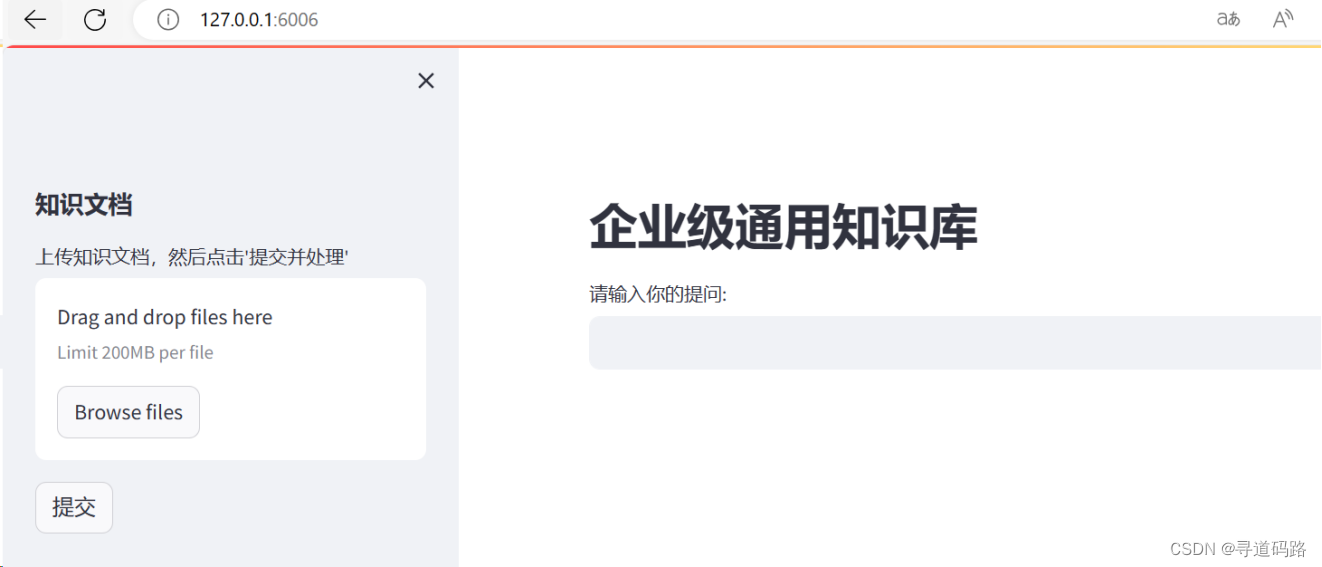
上传知识库,再进行对话测试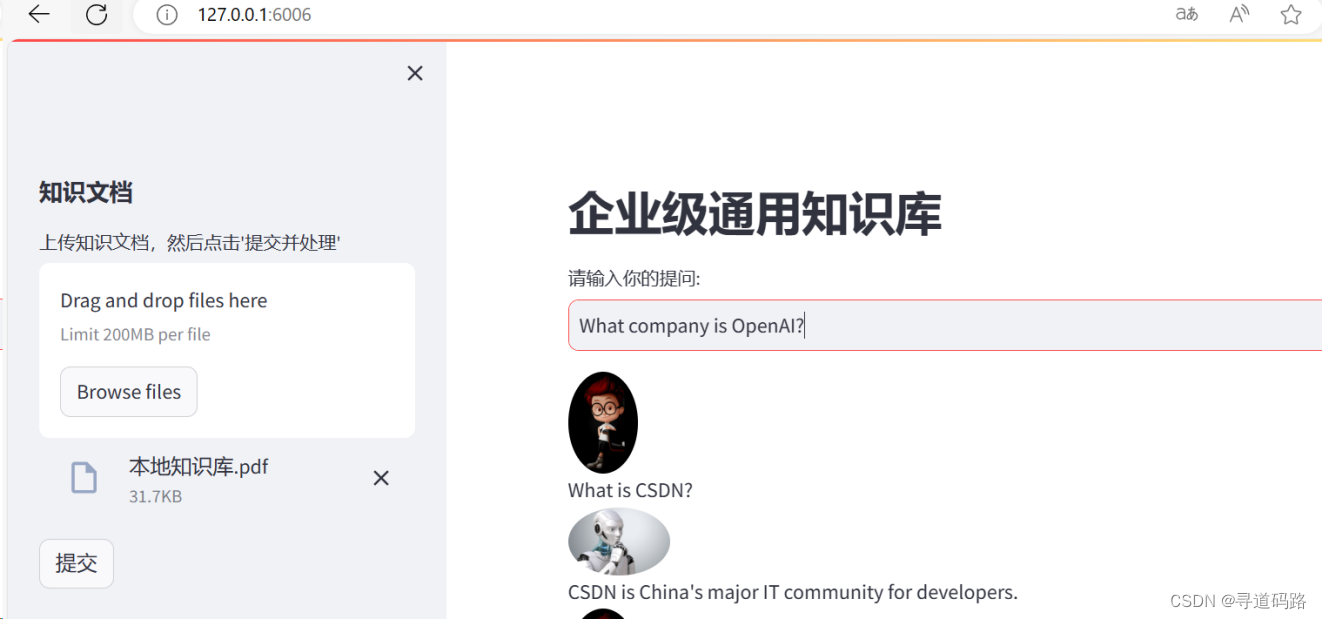
总结
通过私有化部署的企业知识库项目已经成功实践落地。在未来的学习中,我们将进一步探索如何优化整个架构,例如利用微调技术改善知识库性能,优化Prompt的设计,集成更强大的外挂工具以满足特殊业务需求,以及如何加强大模型应用的安全性,包括加入模型审查流程等。
?系列篇章:AI大模型探索之路-实战篇2:基于CVP架构-企业级知识库实战落地 ?更多专栏系列文章:AIGC-AI大模型探索之路
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。
以上就是关于AI大模型探索之路-实战篇3:基于私有模型GLM-企业级知识库开发实战相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!












