ECharts海量数据渲染解决卡顿的4种方式
本文主要讲解关于ECharts海量数据渲染解决卡顿的4种方式相关内容,让我们来一起学习下吧!
场景
周五进行需求评审的时候;
出现了一个图表,本身一个图表本没有什么稀奇的;
可是产品经理在图表的上的备注,让我觉得这个事情并不简单;
那个图表的时间跨度可以是月,年,而且时间间隔很短;
这让我意识到事情并不是想的那样简单;
然后经过简单的询问:如果选择的范围是年;数据可能会上万;
我们都知道;出现上万的数据;
在渲染的时候肯定会出现白屏,操作的时候卡顿;
今天周末,没有事干;来研究研究 Echarts 渲染海量数据
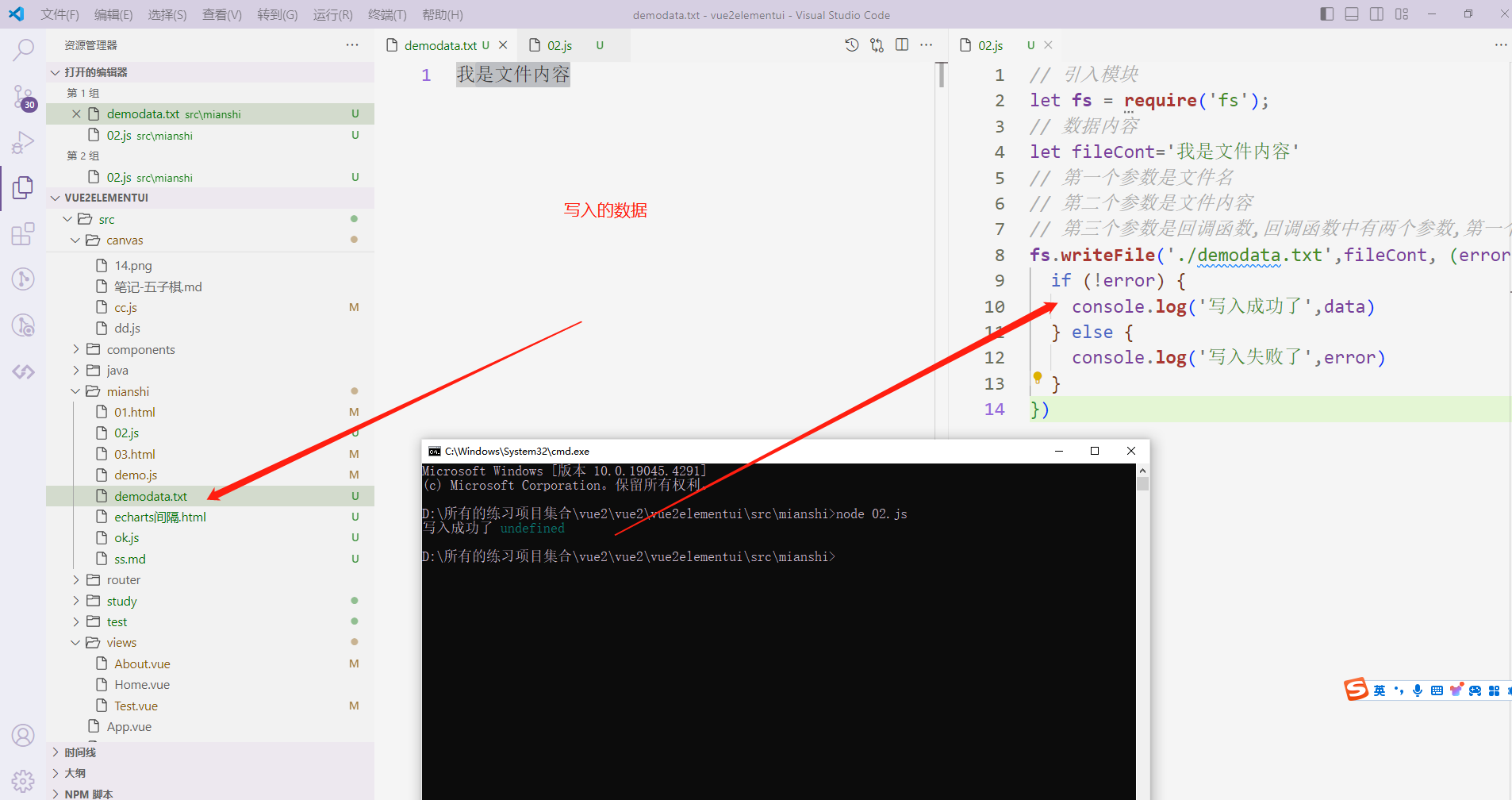
file模块用来写文件
我们首先使用node来生成10万条数据;
借助node的fs模块就行;
如果不会的小伙伴;也不要担心;超级简单
// 引入模块
let fs = require('fs');
// 数据内容
let fileCont='我是文件内容'
/**
* 第一个参数是文件名
* 第二个参数是文件内容,这个文件的内容必须是字符串哈(特别注意)
* 第三个参数是回调函数, 回调函数中有两个参数,
* 第一个参数是错误信息,
* 第二个参数是写入成功后的返回值
* */
fs.writeFile('./demodata.txt',fileCont, (error, data) => {
if (!error) {
console.log('写入成功了',data)
} else {
console.log('写入失败了',error)
}
})
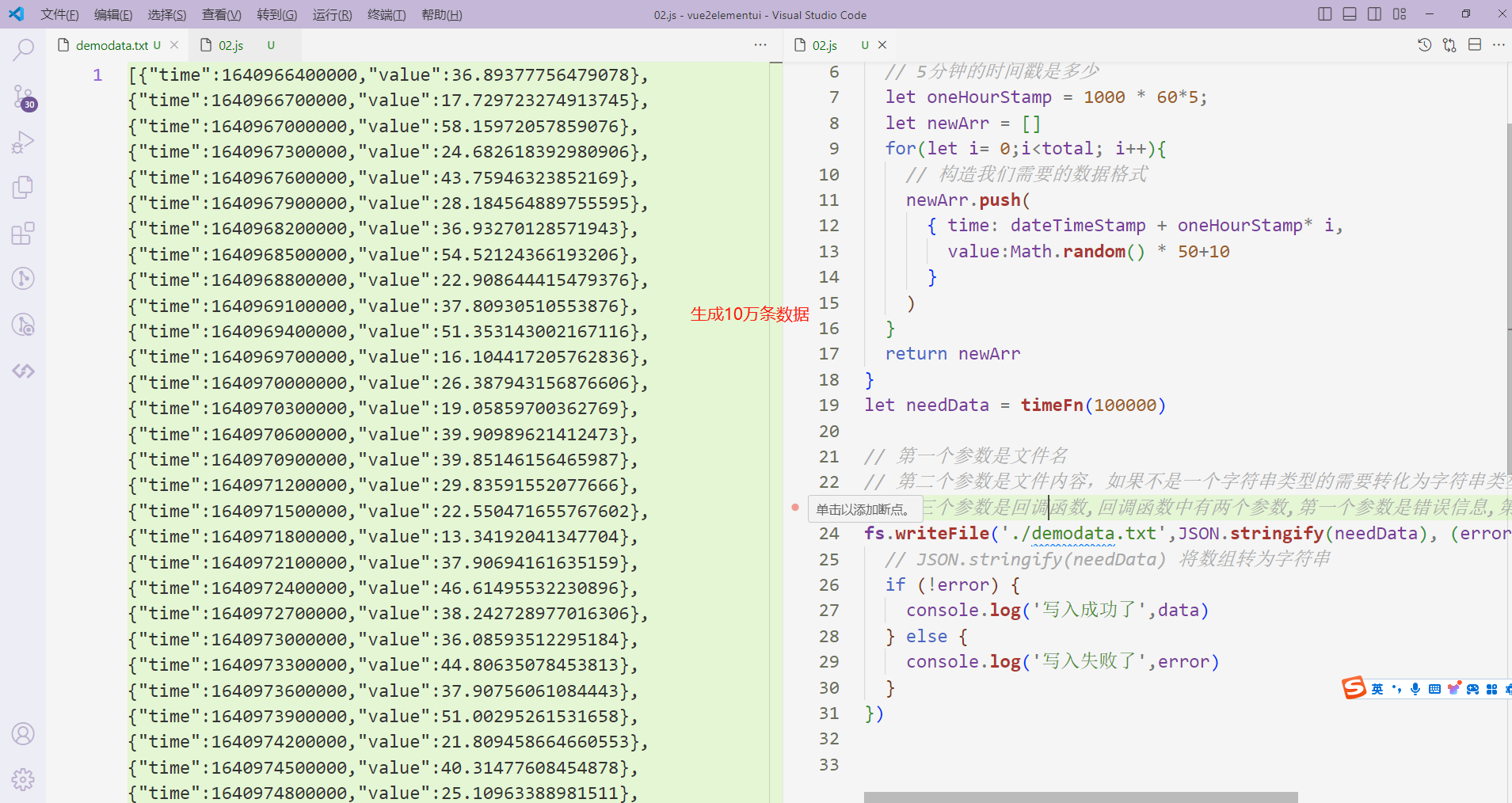
现在我们需要创建一个指定类型的数据格式
我们等会从2022.1.1开始;每条数据间隔5分钟;产生10万条数据。
time的值是时间戳,我们可以通过 new Date().getTime() 来获取
value的值是温度,我们通过Math.random() * 50+10来获取
time的时间间隔是每隔5分钟
数据格式如下
[
{"time":1640966400000,"value":36.57},
{"time":1640966700000,"value":31.68},
]
// 引入模块
let fs = require('fs');
// 生成100000条符合要求的数据格式
function timeFn(total){
// 获取2022年1月1日的时间戳
let dateTimeStamp = new Date(2022, 0, 1).getTime(); // 2022年1月1日
// 5分钟的时间戳是多少
let oneHourStamp = 1000 * 60*5;
let newArr = []
for(let i= 0;i<total; i++){
// 构造我们需要的数据格式
newArr.push(
{ time: dateTimeStamp + oneHourStamp* i,
value:Math.random() * 50+10
}
)
}
return newArr
}
let needData = timeFn(100000)
fs.writeFile('./demodata.js',JSON.stringify(needData), (error, data) => {
// JSON.stringify(needData) 将数组转为字符串
if (!error) {
console.log('写入成功了',data)
} else {
console.log('写入失败了',error)
}
})
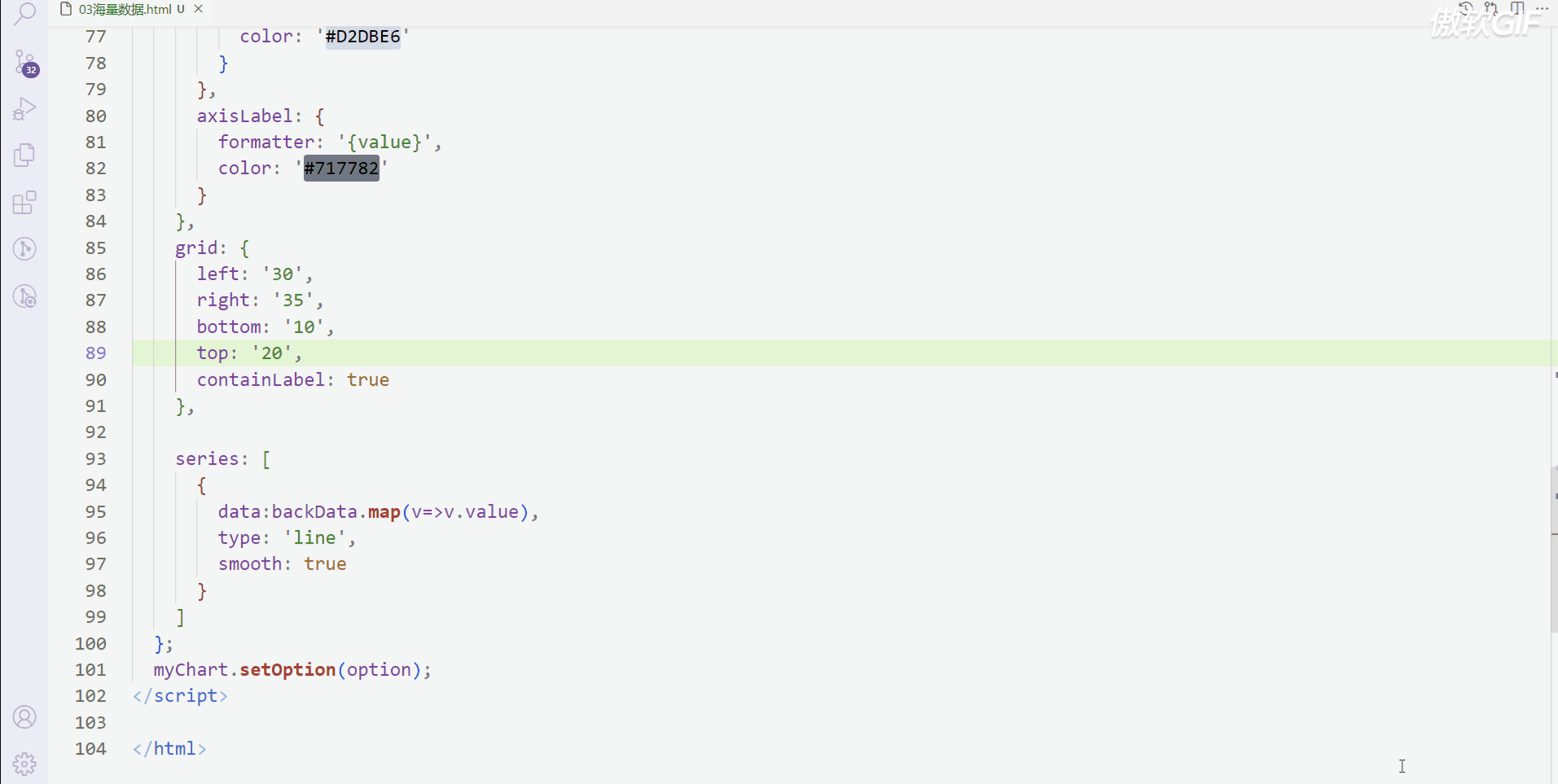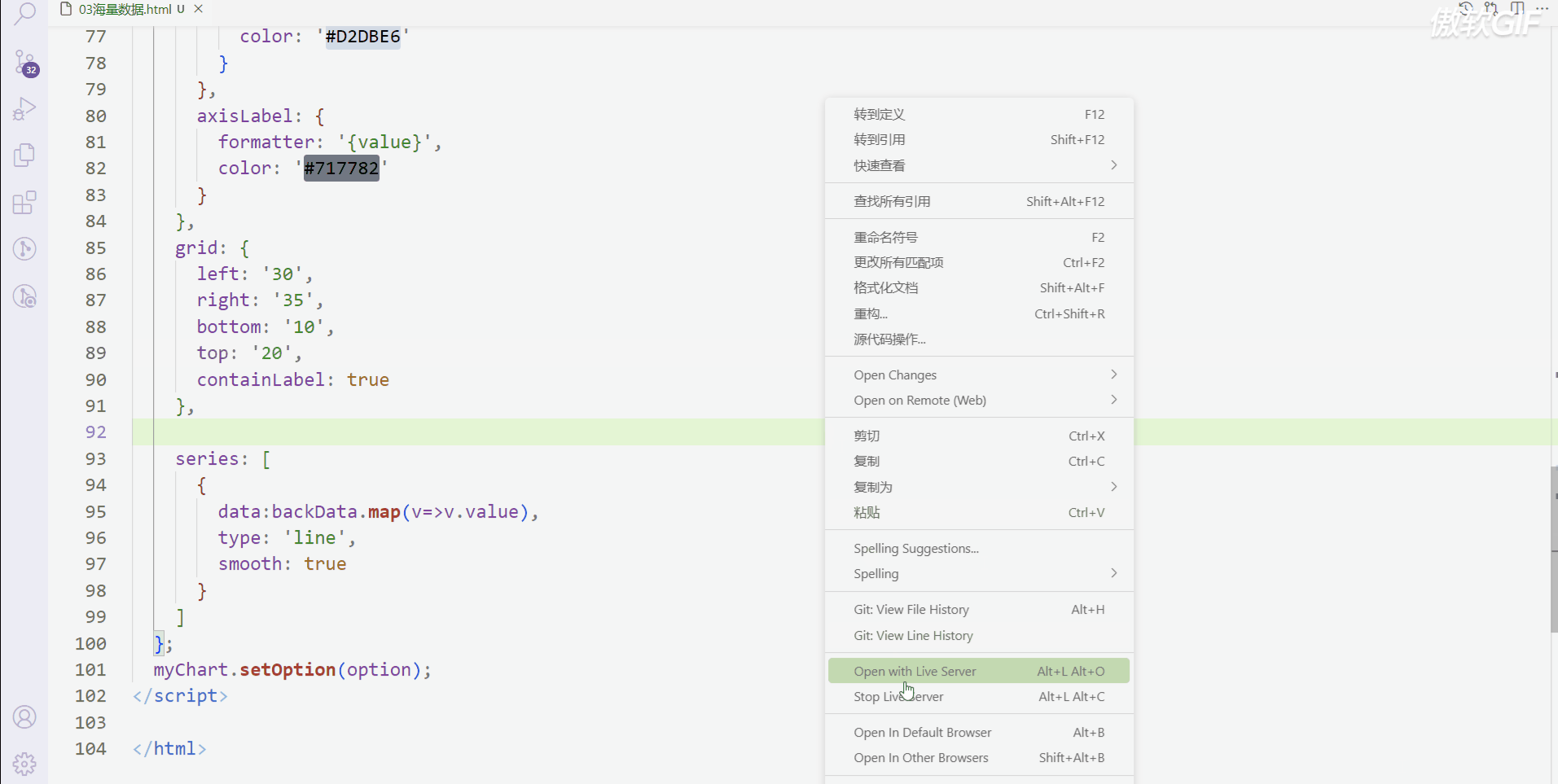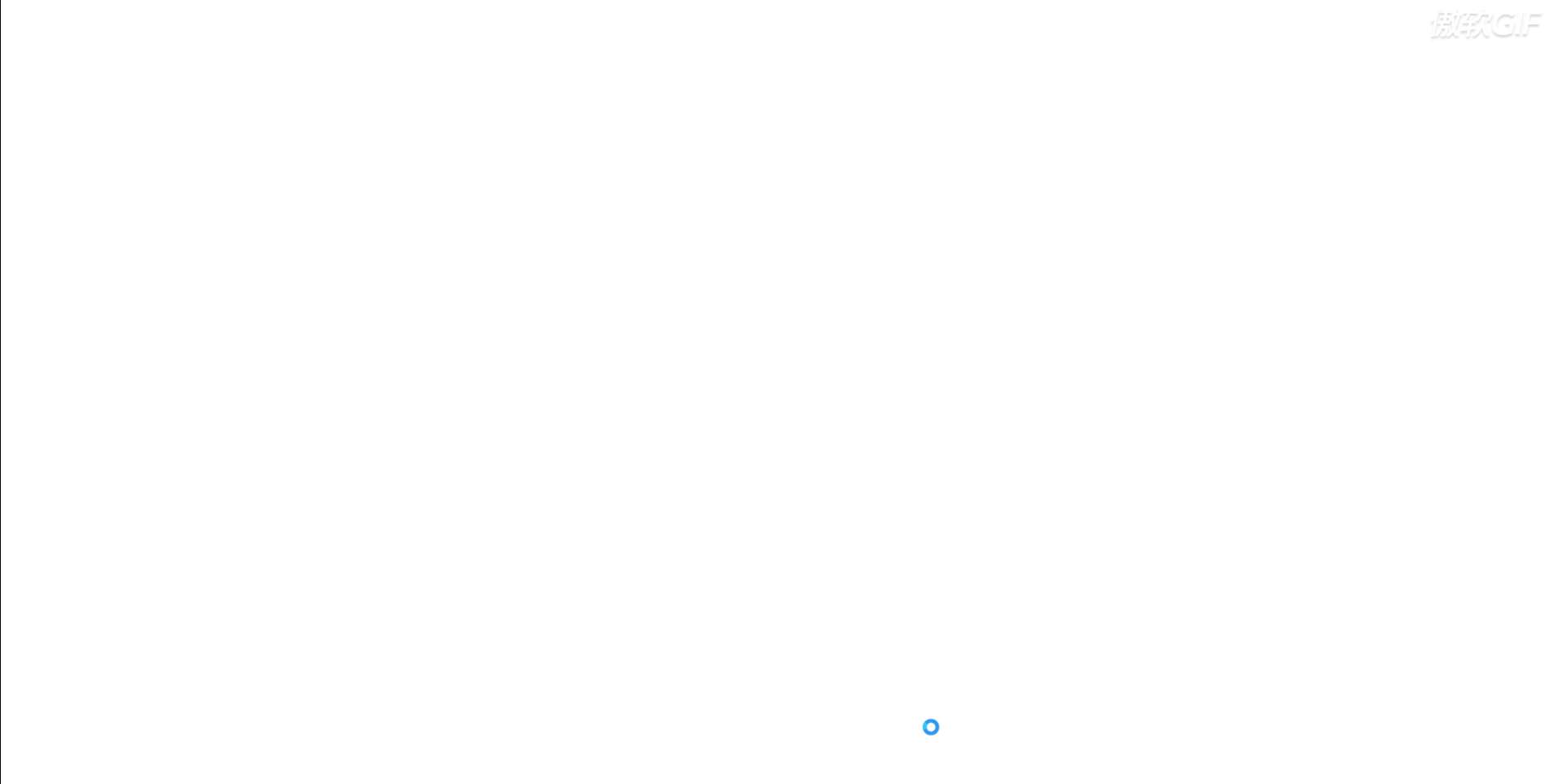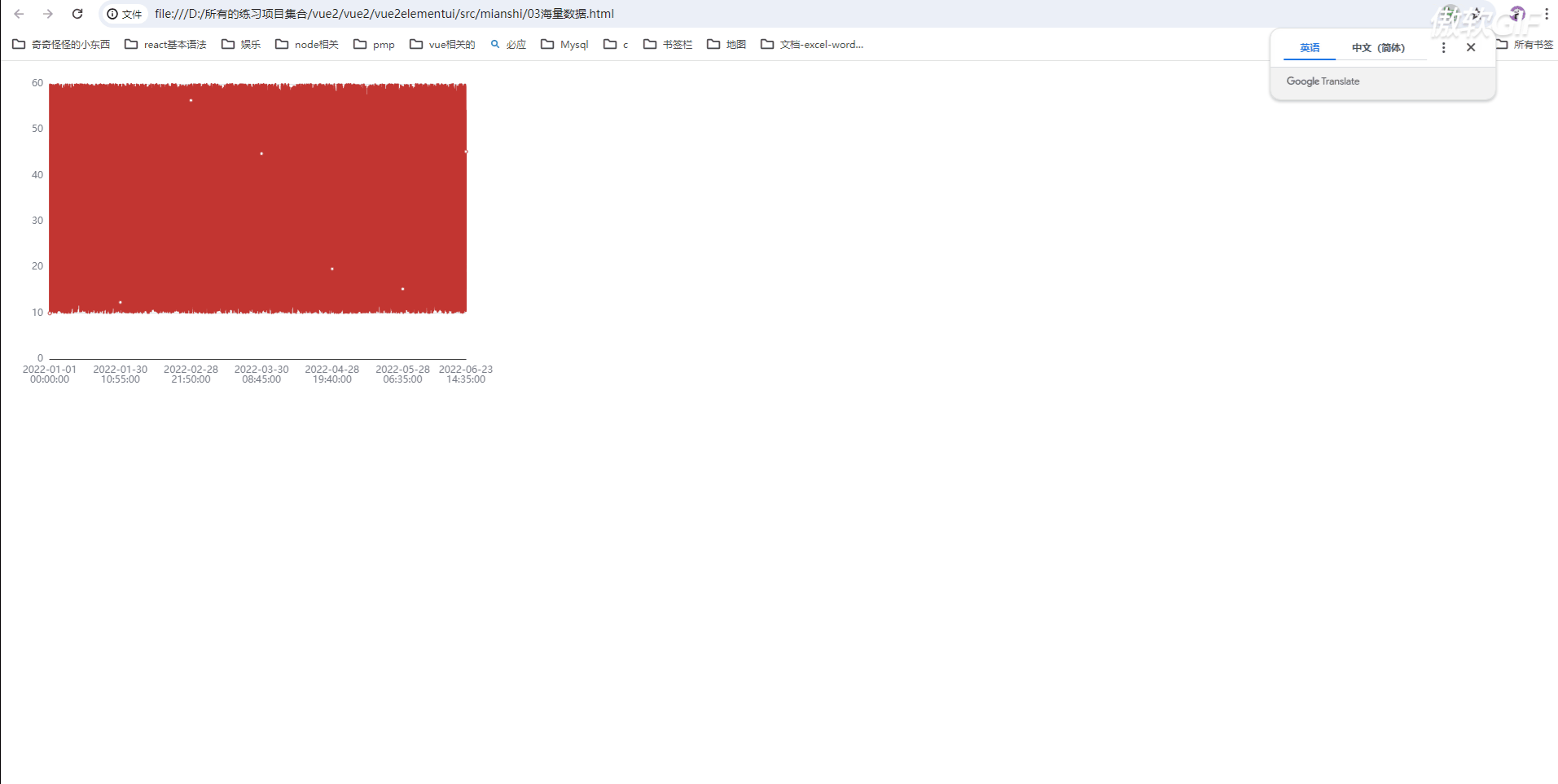
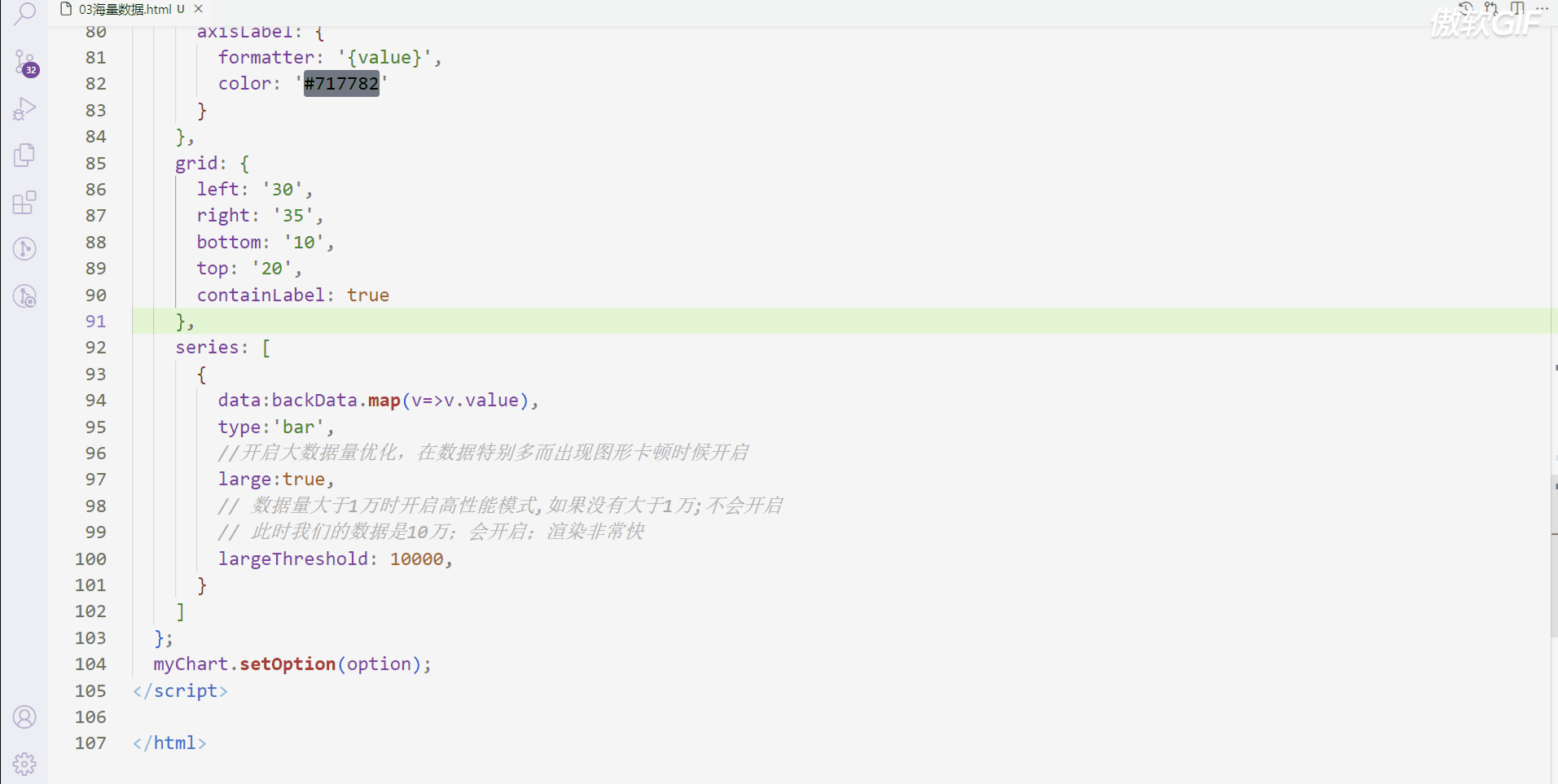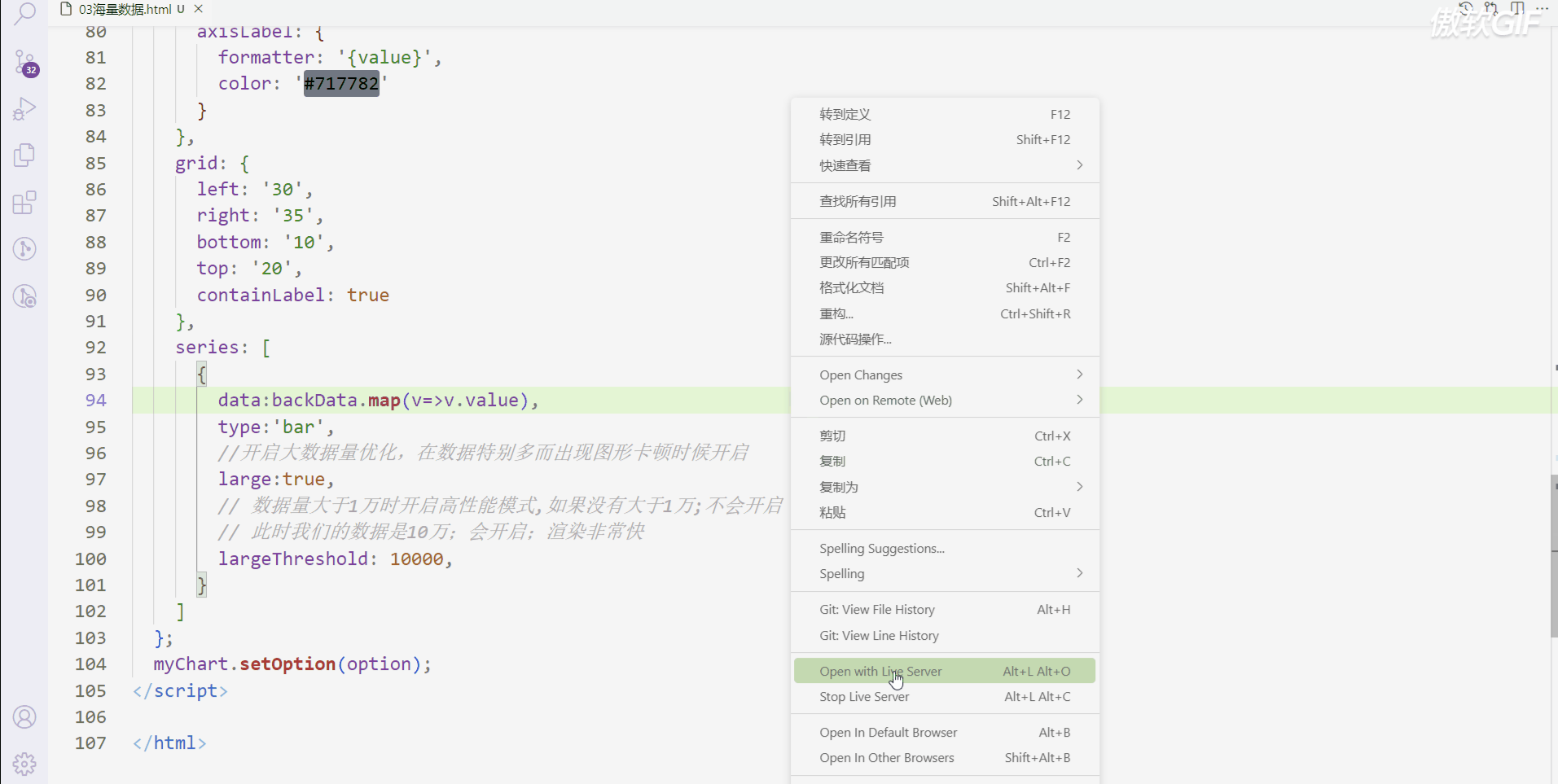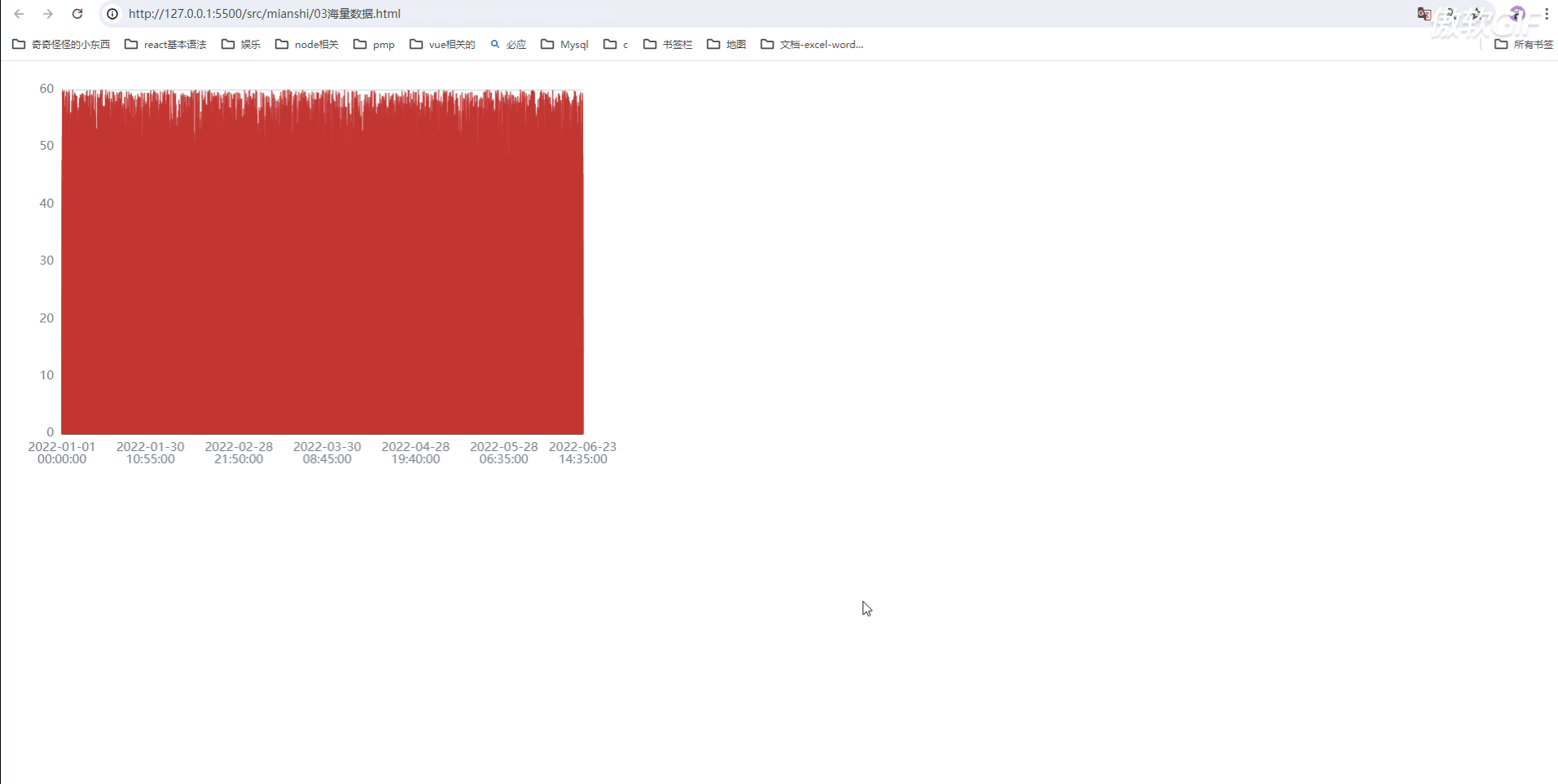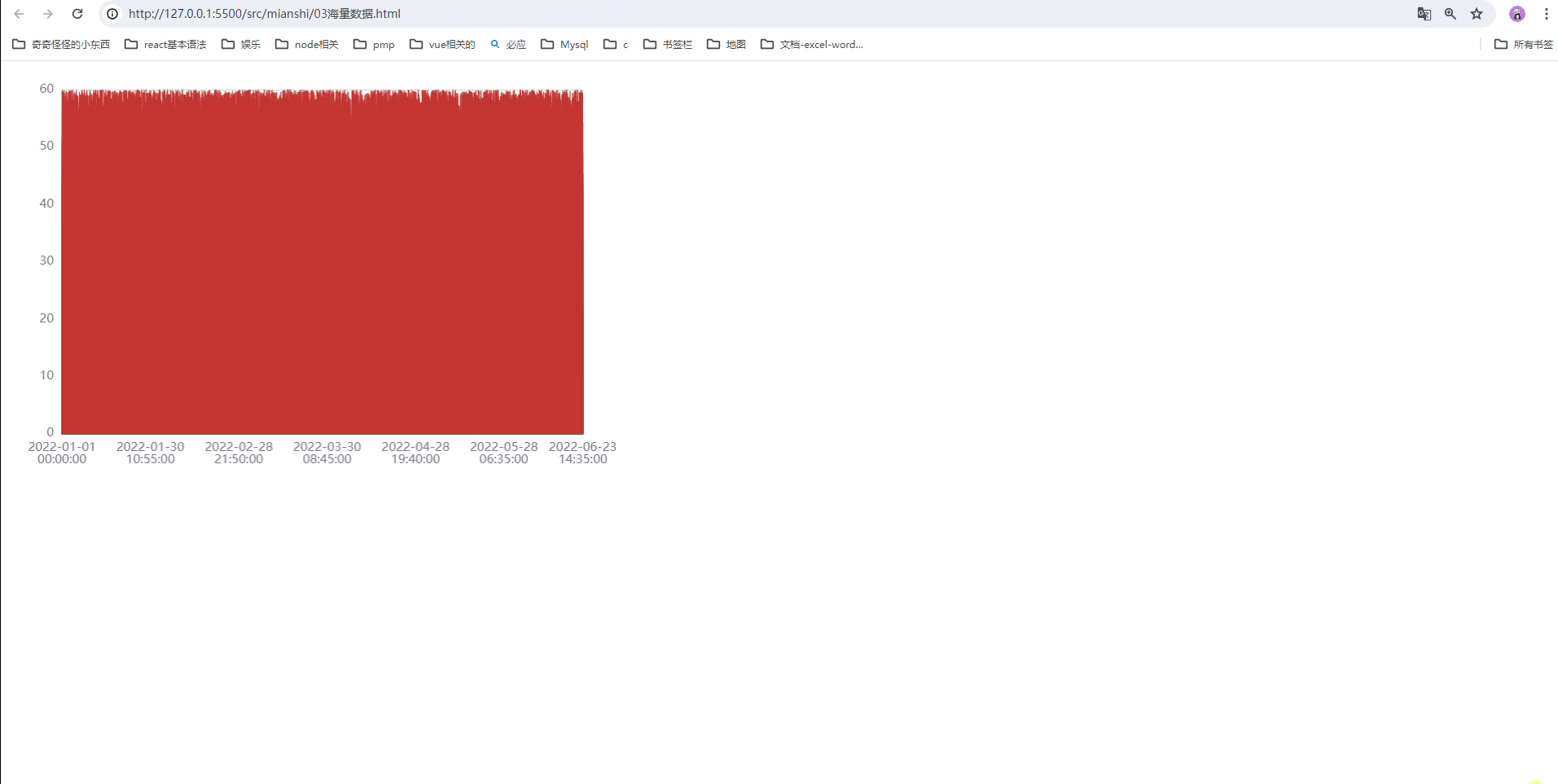
10万条数据渲染耗时10秒,且页面非常卡顿
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="../allechart/echarts.js"></script>
<script src="./demodata.js"></script>
</head>
<body>
<div style="width: 598px;height: 400px;" id="box"></div>
</body>
<script>
function backTime(value){
let date = new Date(value);
// 获取年份、月份和日期
let year = date.getFullYear();
// 月份从 0 开始,需要加 1
let month = date.getMonth() + 1;
let day = date.getDate();
let hours = date.getHours();
let minutes = date.getMinutes();
let seconds = date.getSeconds();
// 格式化月份和日期为两位数(不足两位时补零)
month = month < 10 ? '0' + month : month;
day = day < 10 ? '0' + day : day;
hours = hours < 10 ? '0' + hours : hours;
minutes = minutes < 10 ? '0' + minutes : minutes;
seconds = seconds < 10 ? '0' + seconds : seconds;
// 返回格式化后的字符串
return year + '-' + month + '-' + day + 'n' + hours + ':' + minutes + ':' + seconds;
}
console.log(backData)
let myChart = echarts.init(document.querySelector('#box'))
let option = {
legend: {
data: ['某城市']
},
tooltip: {
trigger: 'axis',
triggerOn: 'mousemove',
confine: true,
extraCssText: 'white-space: pre-wrap'
},
xAxis: {
type: 'category',
// 返回时间
data: backData.map(v=> backTime(v.time)),
splitLine: { show: false },
lineStyle: {
width: 2
},
axisTick: {
show: false
},
axisLabel:{
// 更改x轴文字颜色的配置
textStyle: {
color: '#717782'
},
showMinLabel: true,
showMaxLabel: true // 固定显示X轴的最后一条数据
},
},
yAxis: {
type: 'value',
axisLine: {
show: false
},
axisTick: {
show: false
},
splitLine: {
lineStyle: {
color: '#D2DBE6'
}
},
axisLabel: {
formatter: '{value}',
color: '#717782'
}
},
grid: {
left: '30',
right: '35',
bottom: '10',
top: '20',
containLabel: true
},
series: [
{
data:backData.map(v=>v.value),
type: 'line',
smooth: true
}
]
};
myChart.setOption(option);
</script>
</html>
发现的问题
我们发现渲染时间非常久(需要10多秒),而且页面卡顿;
有没有好的办法来解决这个问题呢;
是有的,最好的使用echarts的dataZoom用于区域缩放;
通过滑块看指定区域的数据,我们来尝试一下
dataZoom的常见属性介绍
type: "slider" || "inside",
slider:这种类型会在图表的一侧添加一个滑动条,
用户可以通过拖动滑动条来改变数据窗口的范围,从而实现数据的缩放。
inside:这种类型缩放组件是内置于坐标系中的,
用户可以通过鼠标滚轮、触屏手指滑动等方式来操作数据的缩放。
简单点说:slider会产生一个滚动条,inside不会
xAxisIndex: 可以是一个数字,表示特定的X轴索引;
也可以是一个数组,表示同时控制多个X轴。
xAxisIndex: 0, 控制第1条数据开始
start: 0, 数据窗口范围的起始百分比。范围是:0 ~ 100。表示 0% ~ 100%。
end: 1, 数据窗口范围的结束百分比。范围是:0 ~ 100。
minSpan: 0, 用于限制窗口大小的最小值(百分比值),取值范围是 0 ~ 100。
maxSpan: 10, 用于限制窗口大小的最大值(百分比值),取值范围是 0 ~ 100。
特别提醒:start: 设置为0;说明是从第1条数据开始的;
那么xAxisIndex就必须是0;
因为xAxisIndex不是0,他们就互相矛盾了;
minSpan 和 maxSpan一般配合使用;主要是用于只展示某一个区间;
无论用户怎么缩放;都会在这个区间
我们使用 dataZoom 来处理海量的数据
... 其他配置项
dataZoom: [
{
type: "slider", // 滑块类型 值有slider和inside
xAxisIndex: [0],
start: 0,
end: 1,
minSpan: 0, // 用于限制窗口大小的最小值(百分比值),取值范围是 0 ~ 100。
maxSpan: 10,
},
],
series: [
{
data:backData.map(v=>v.value),
type: 'line',
smooth: true
}
]
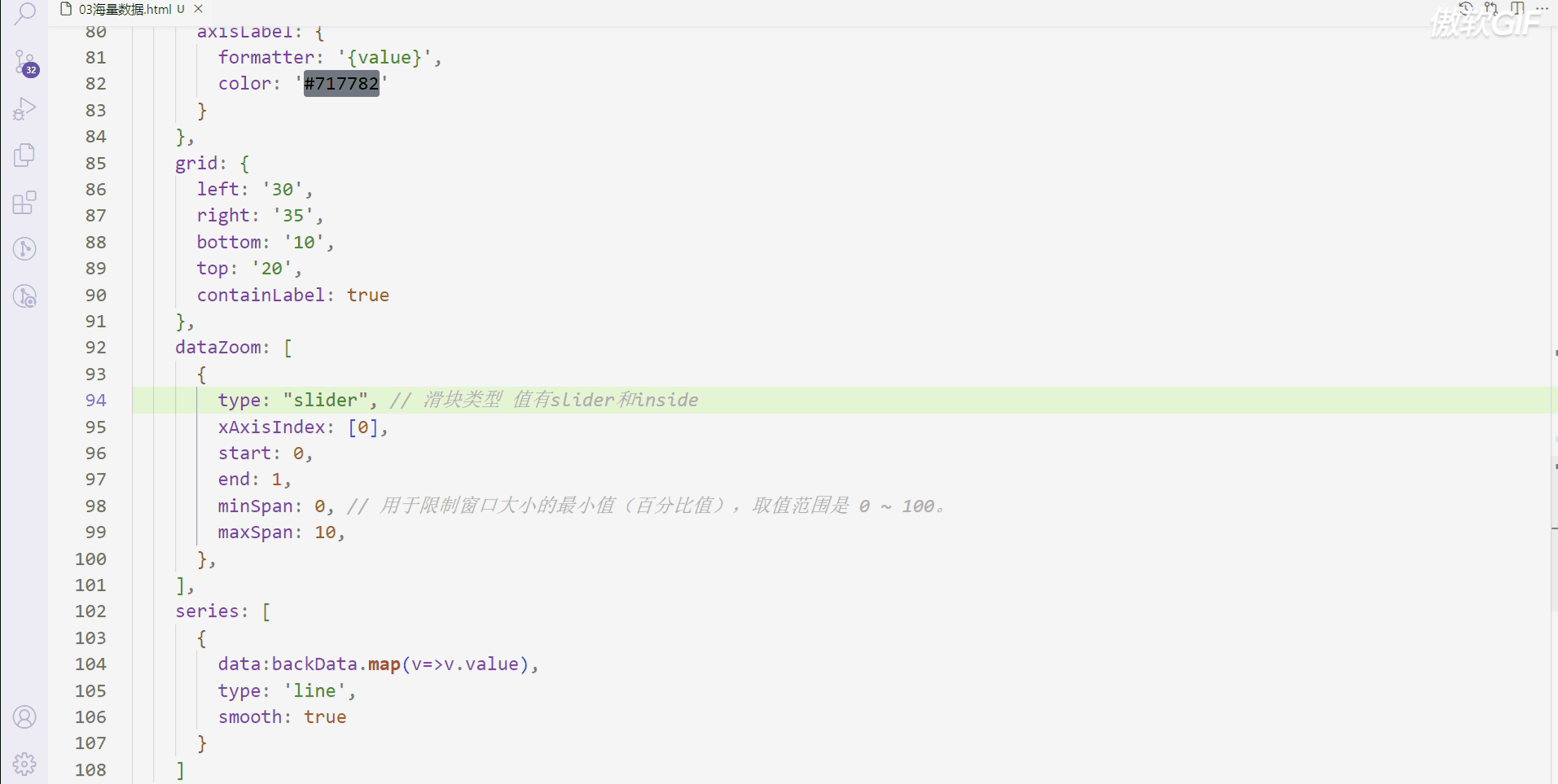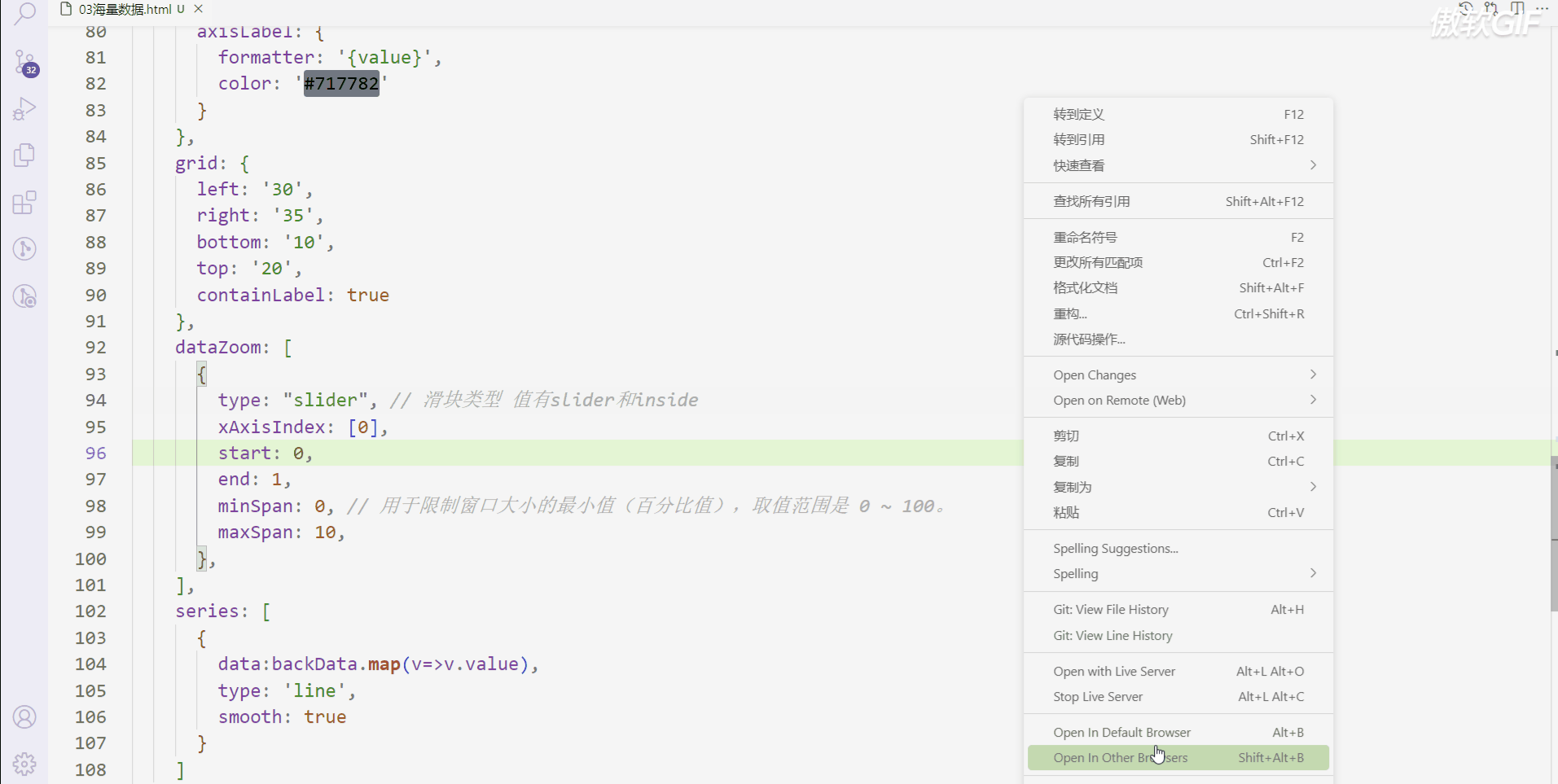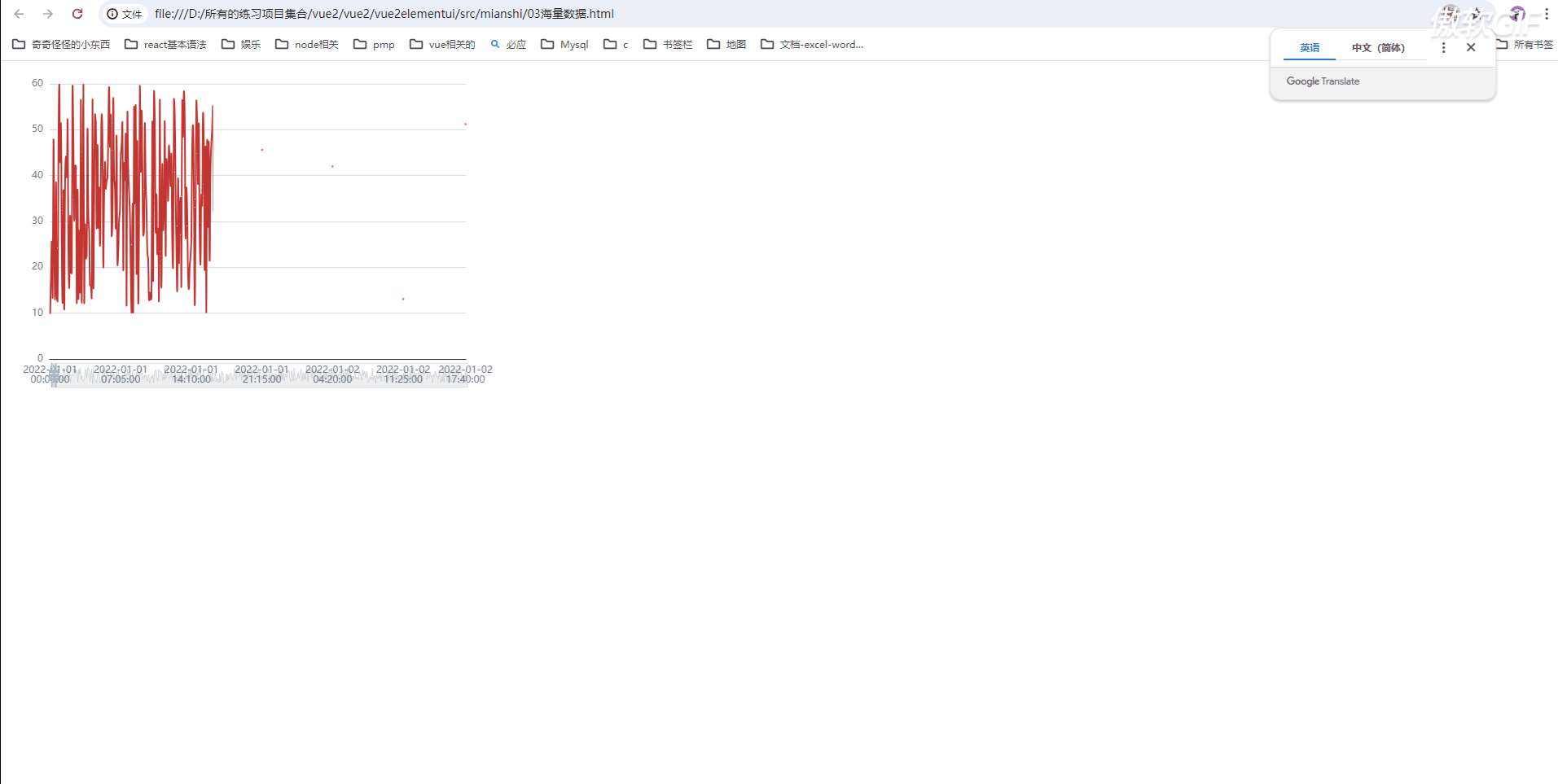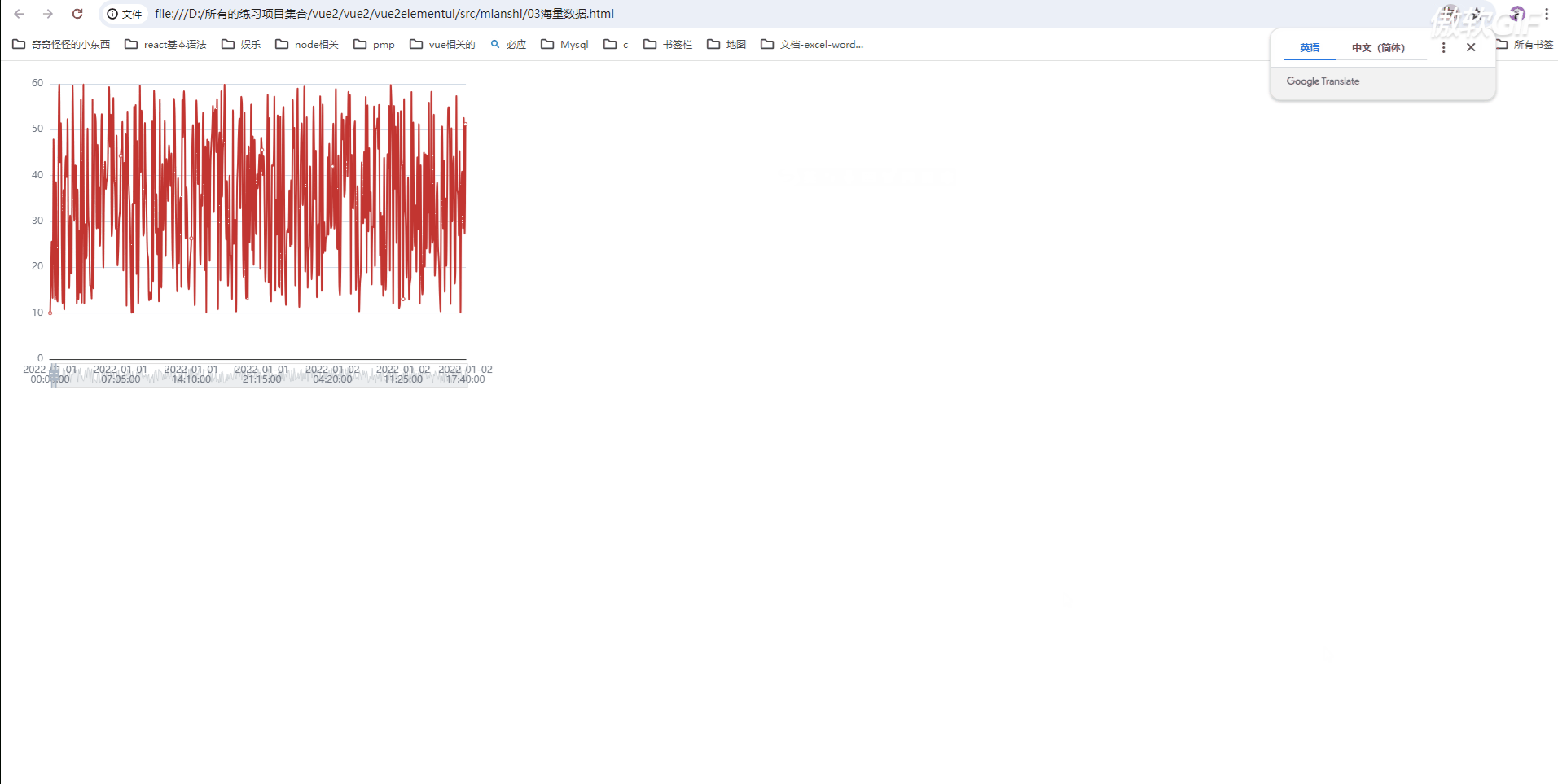
配置之后,我们发现渲染非常流畅
通过配置前和配置后的图的对比
我们发现配置之后;页面渲染速度非常快;
打开页面就渲染完成,压根想不到是10万条数据;
说明通过 dataZoom 是非常有效的
dataZoom处理海量数据的优缺点
优点:配置简单;
缺点:只能看指定局部的数据;无法看整体数据
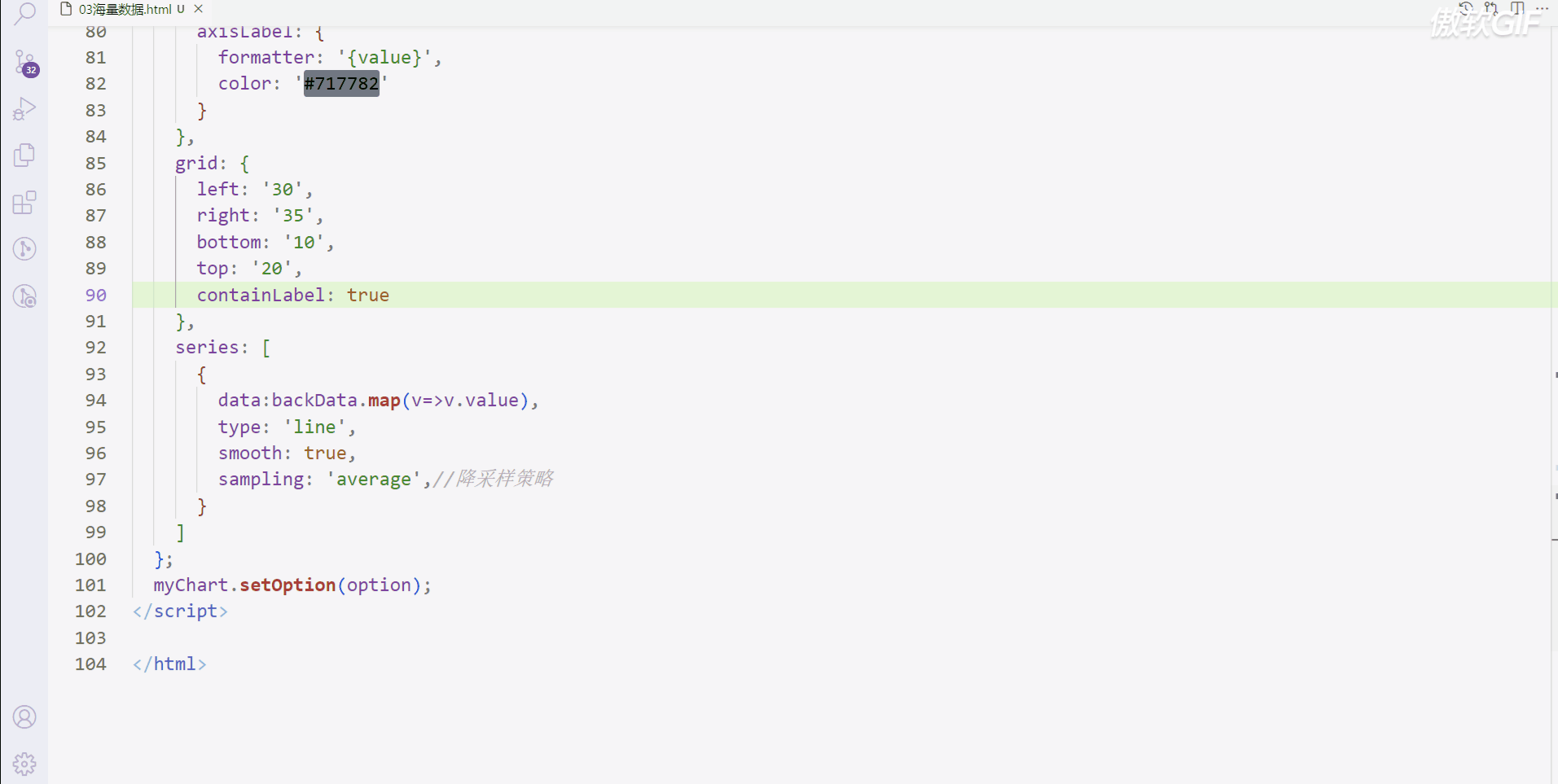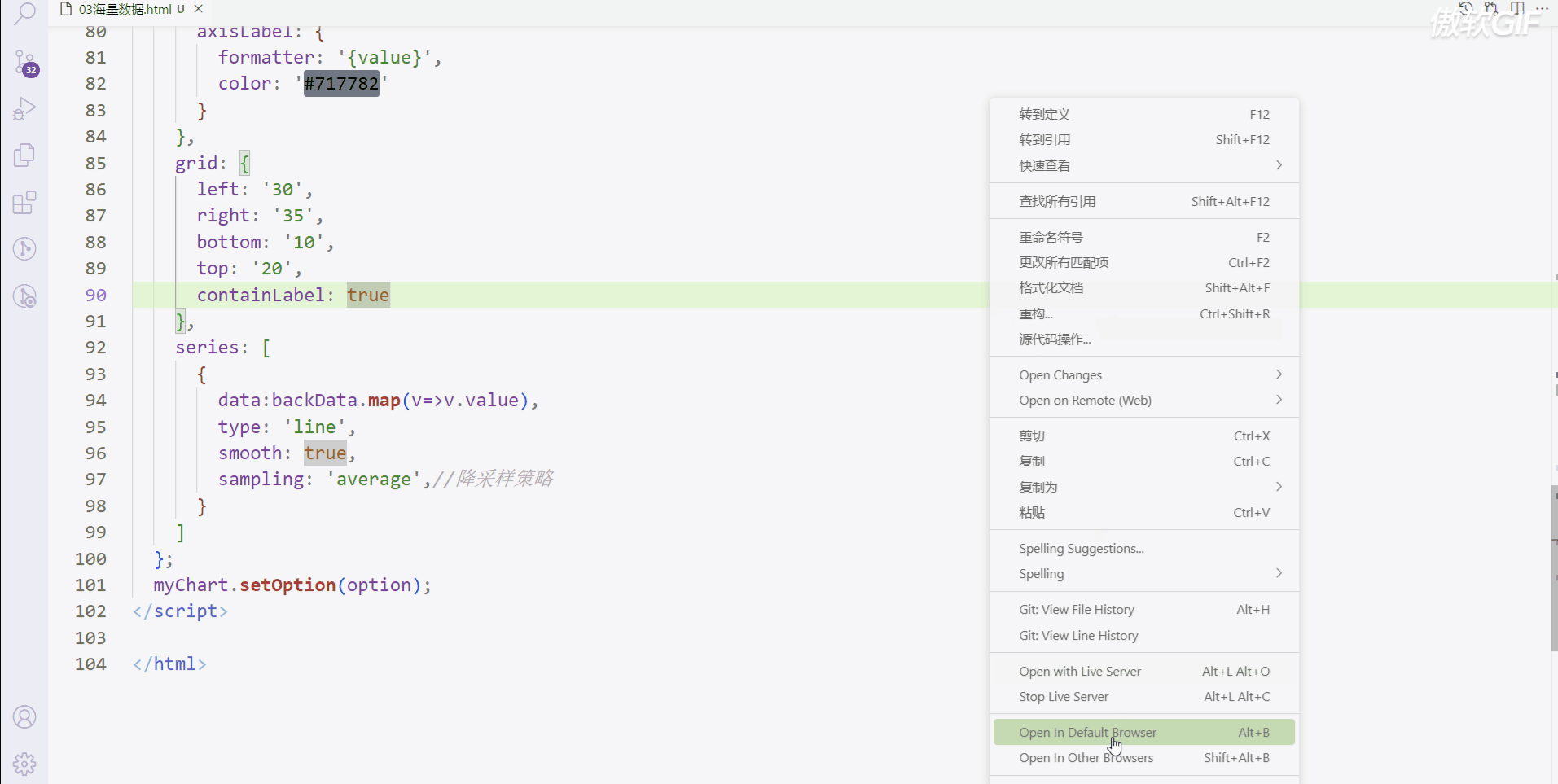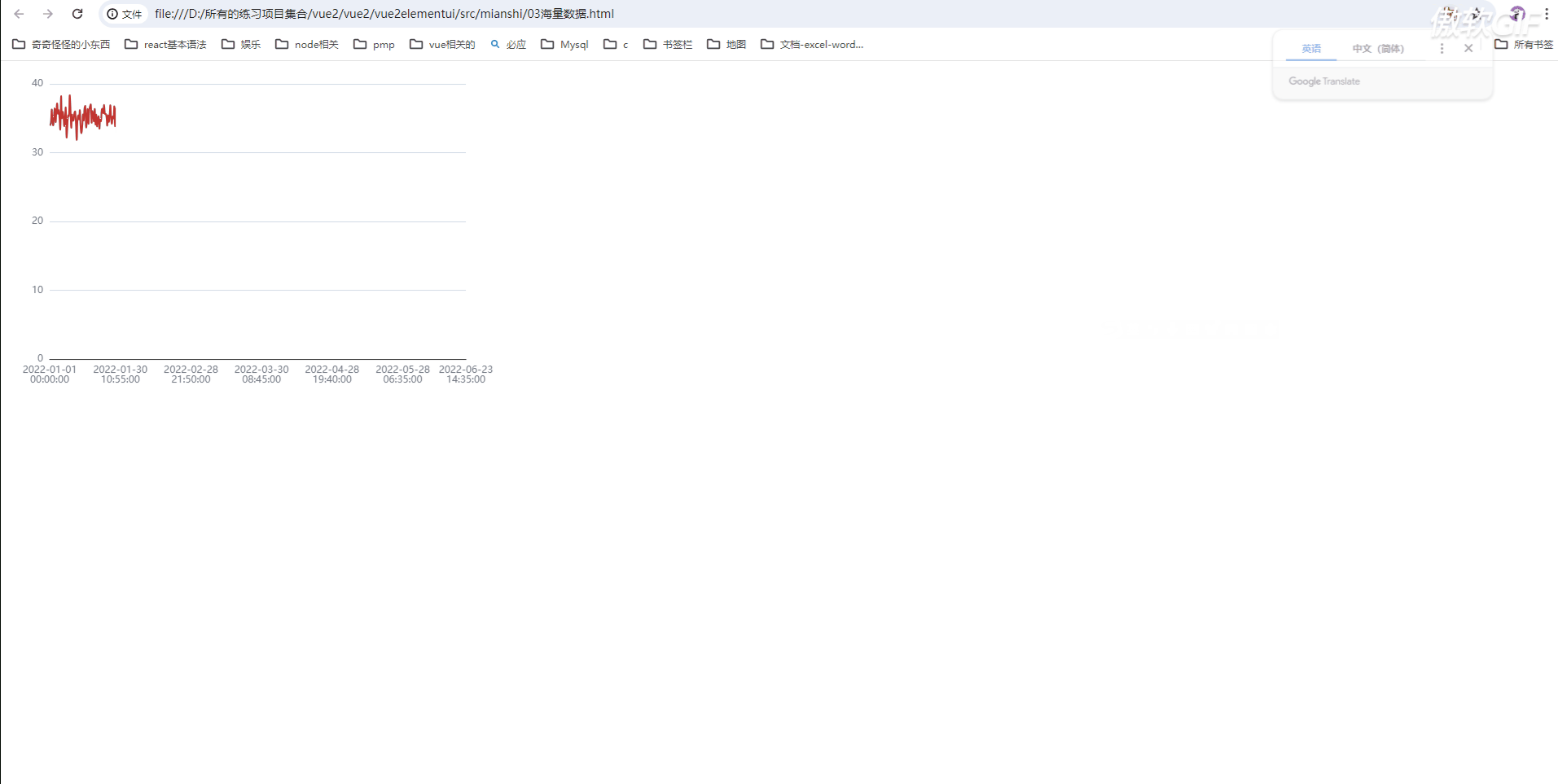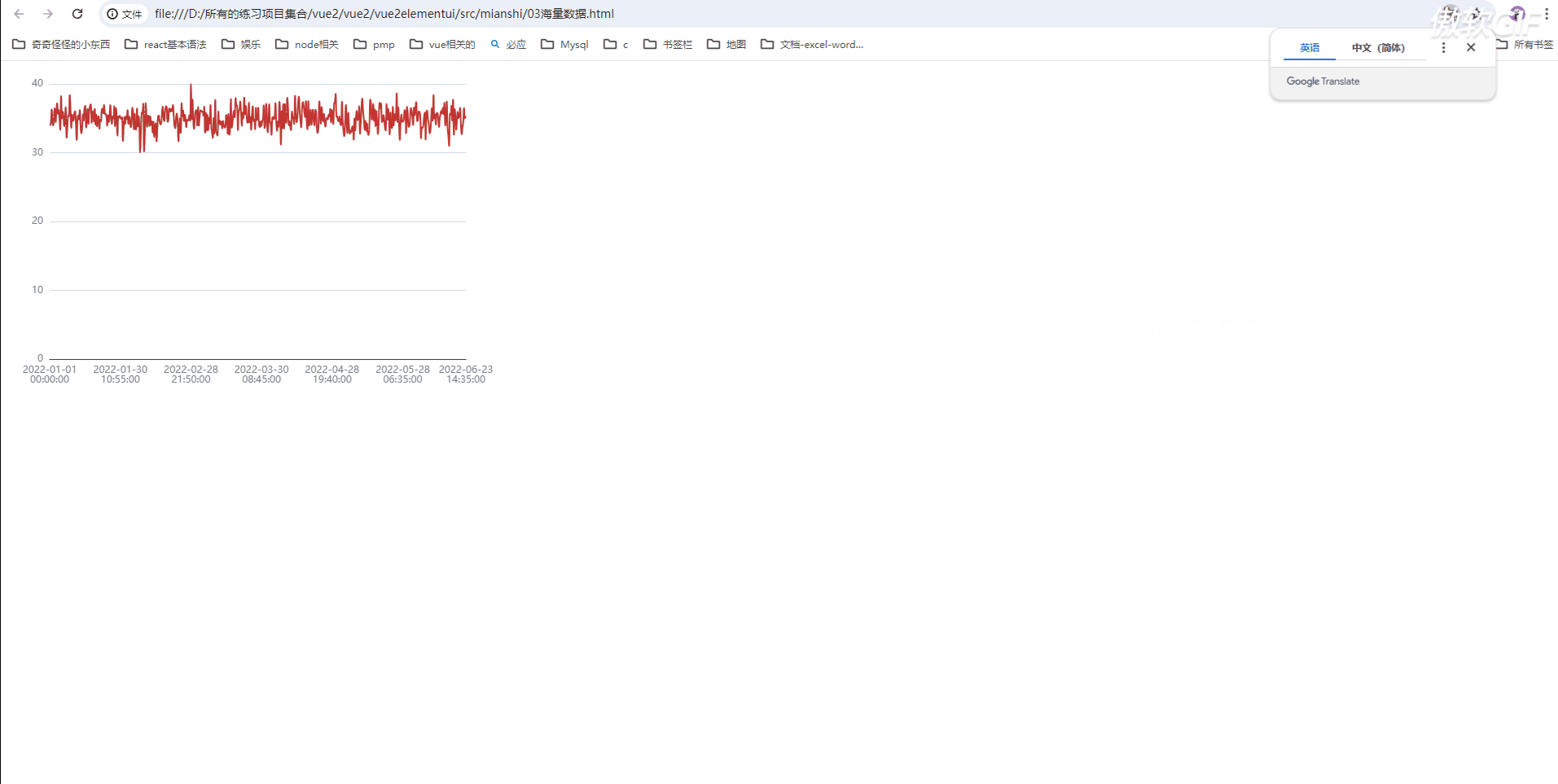
其他办法 sampling 降采样策略 sampling: 'average'
series: [
{
data:backData.map(v=>v.value),
type: 'line',
smooth: true,
sampling: 'average',//' 表示采用平均值采样策略
}
]
sampling的几个值
'lttb': 采用 Largest-Triangle-Three-Bucket 算法,
可以最大程度保证采样后线条的趋势,形状和极值。
不过有可能会造成页面渲染时间长
'average': 取过滤点的平均值
'min': 取过滤点的最小值
'max': 取过滤点的最大值
'minmax': 取过滤点绝对值的最大极值 (从 v5.5.0 开始支持)
'sum': 取过滤点的和
sampling 降采样策略 sampling: 'lttb'
series: [
{
data:backData.map(v=>v.value),
type: 'line',
smooth: true,
// 采用 Largest-Triangle-Three-Bucket 算法,
// 可以最大程度保证采样后线条的趋势,形状和极值。
// 不过有可能会造成页面渲染时间长
sampling: 'lttb'
}
]
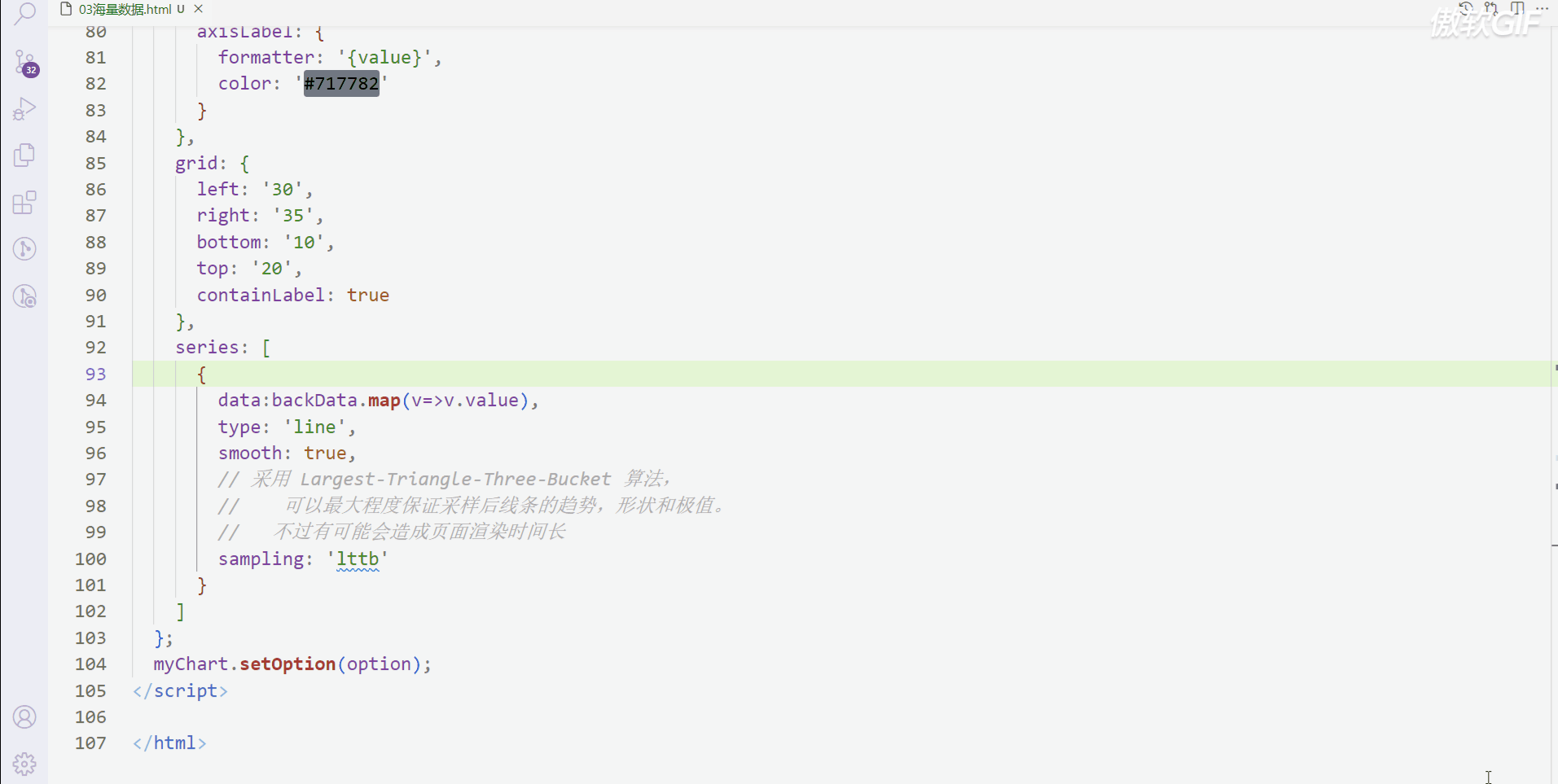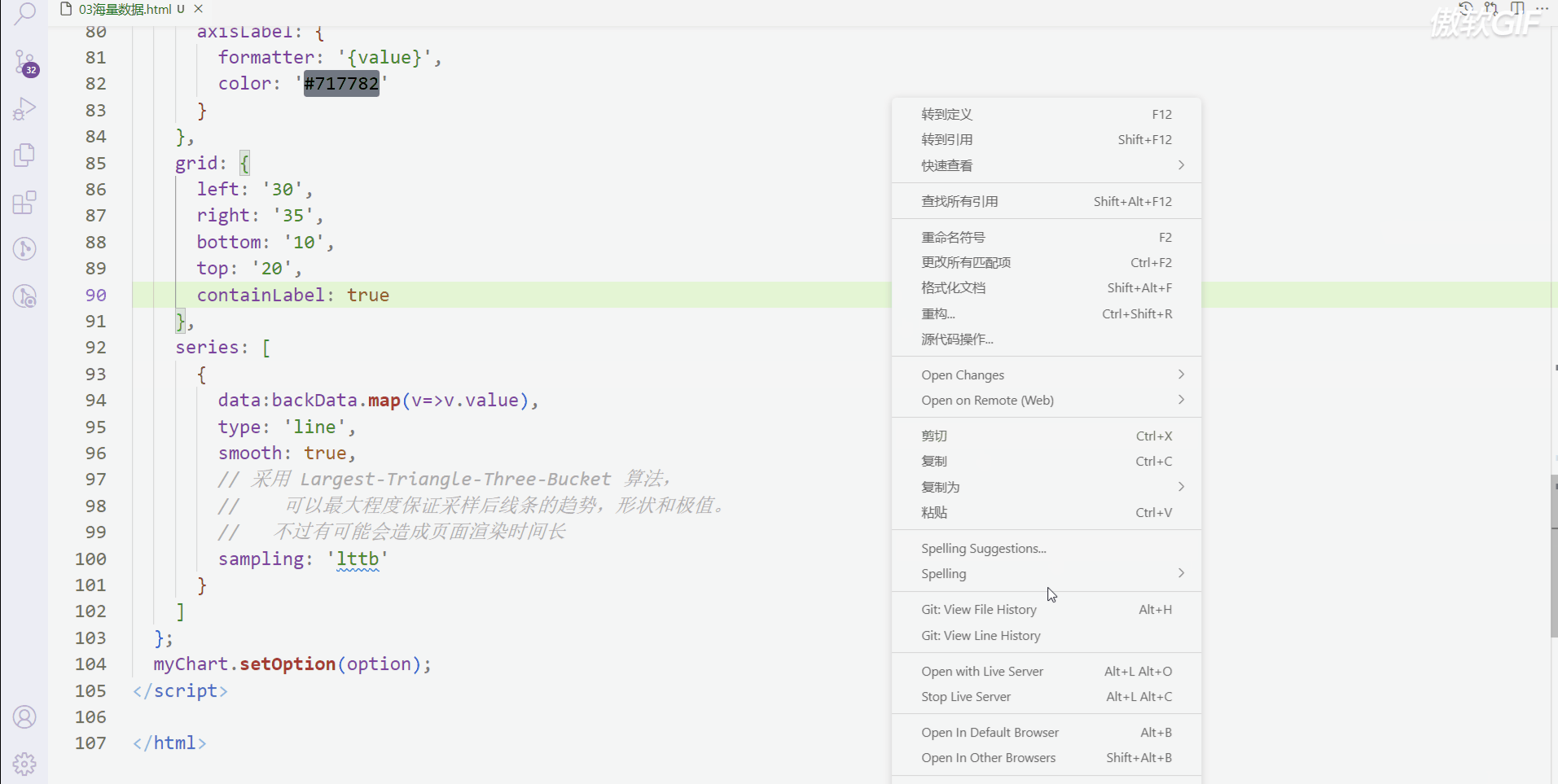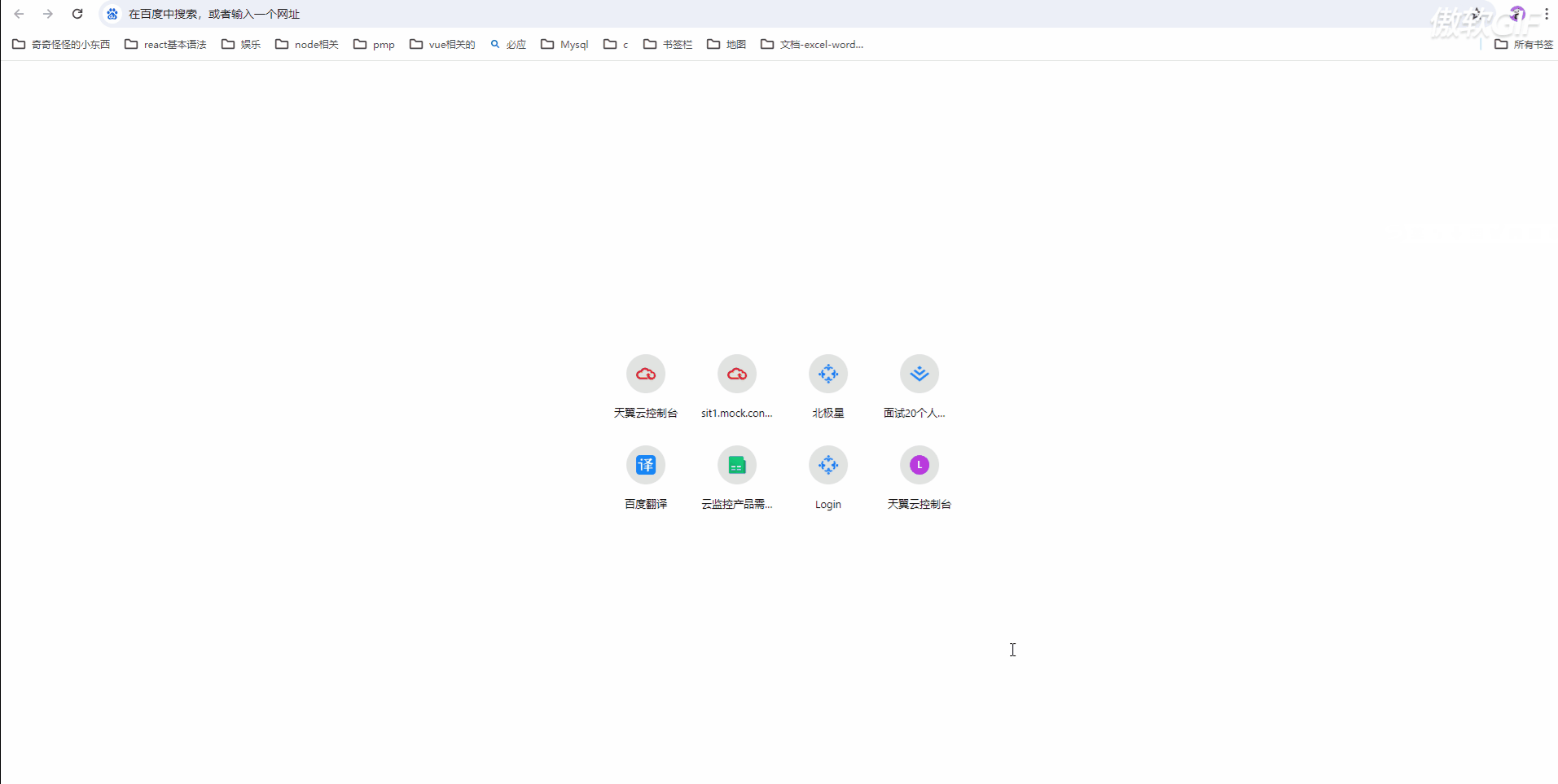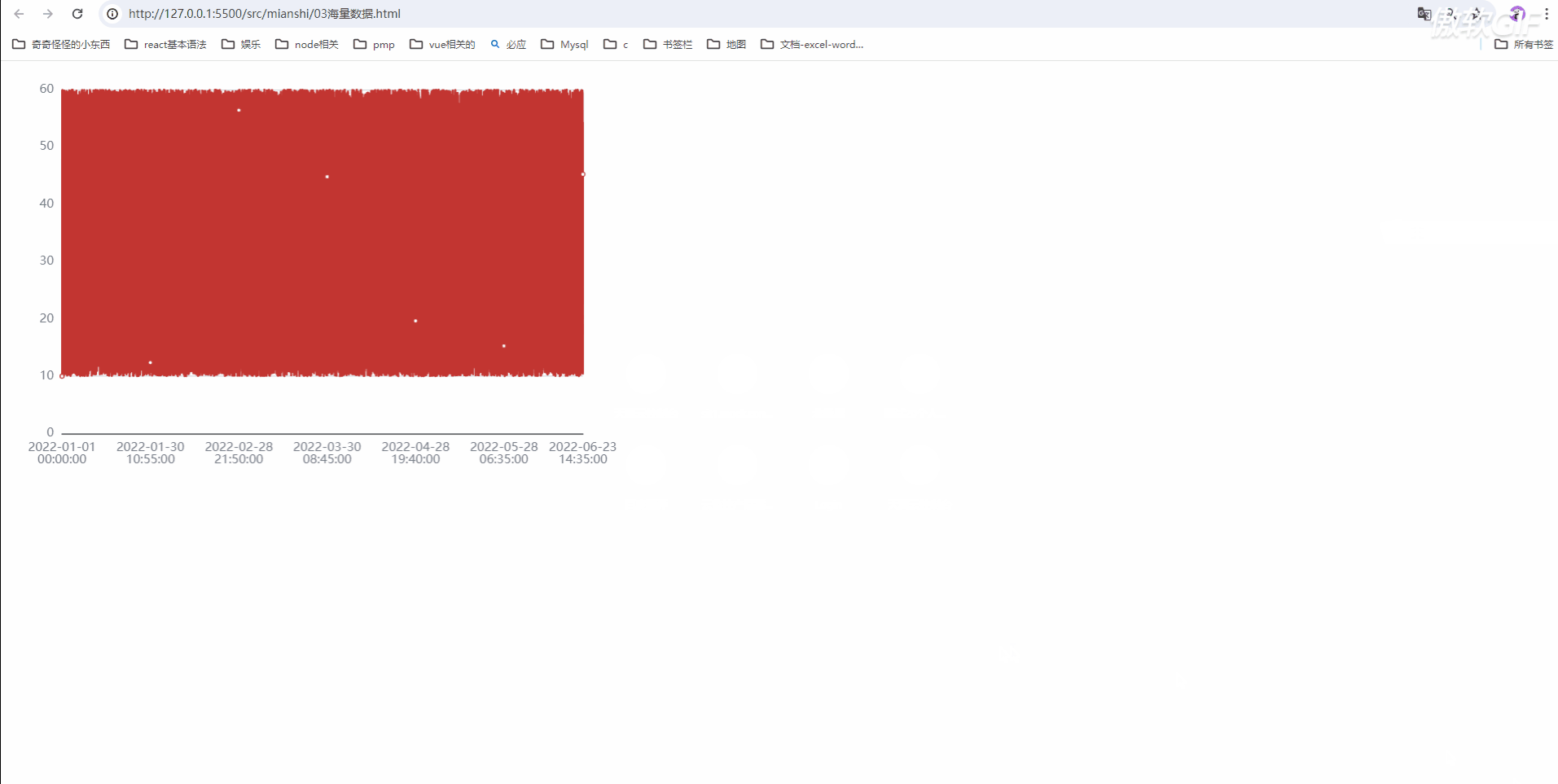
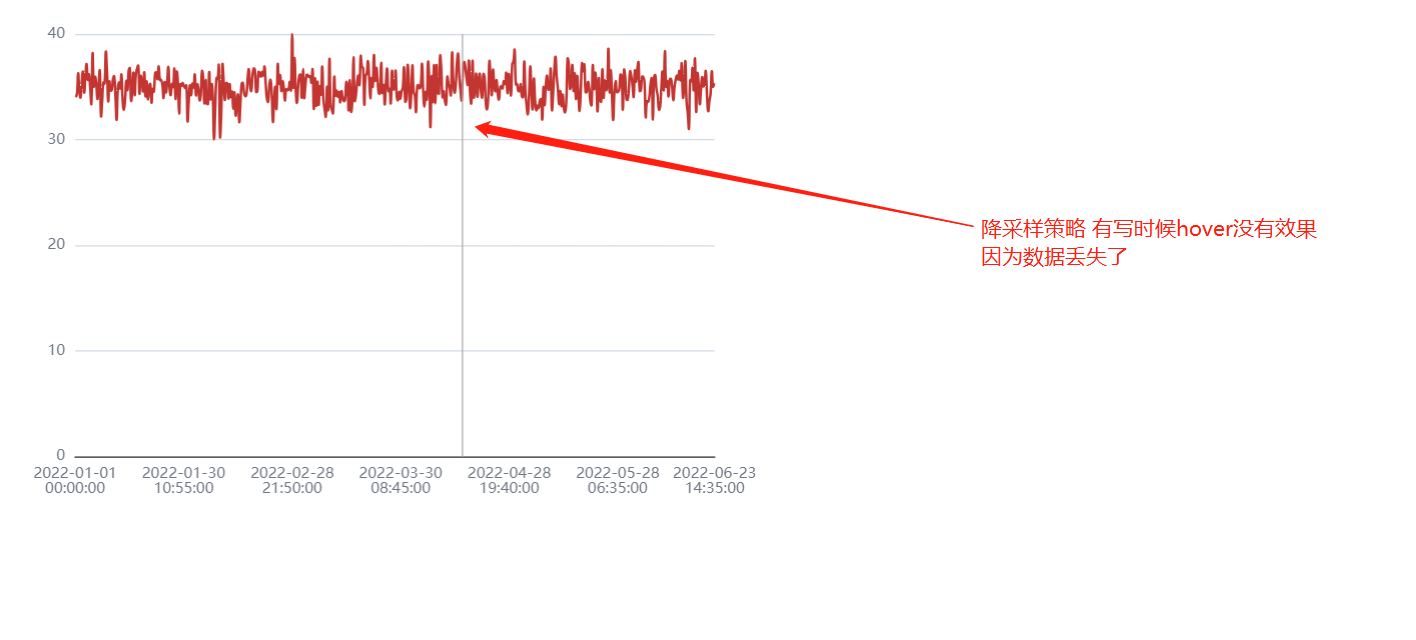
降采样策略 sampling 的优缺点
优点:可以看见整体的趋势;
缺点:部分数据丢失;tooltip功能可能实现不了
使用 large 属性
series: [
{
data:backData.map(v=>v.value),
type: 'line',
smooth: true,
//开启大数据量优化,在数据特别多而出现图形卡顿时候开启
large:true,
}
]
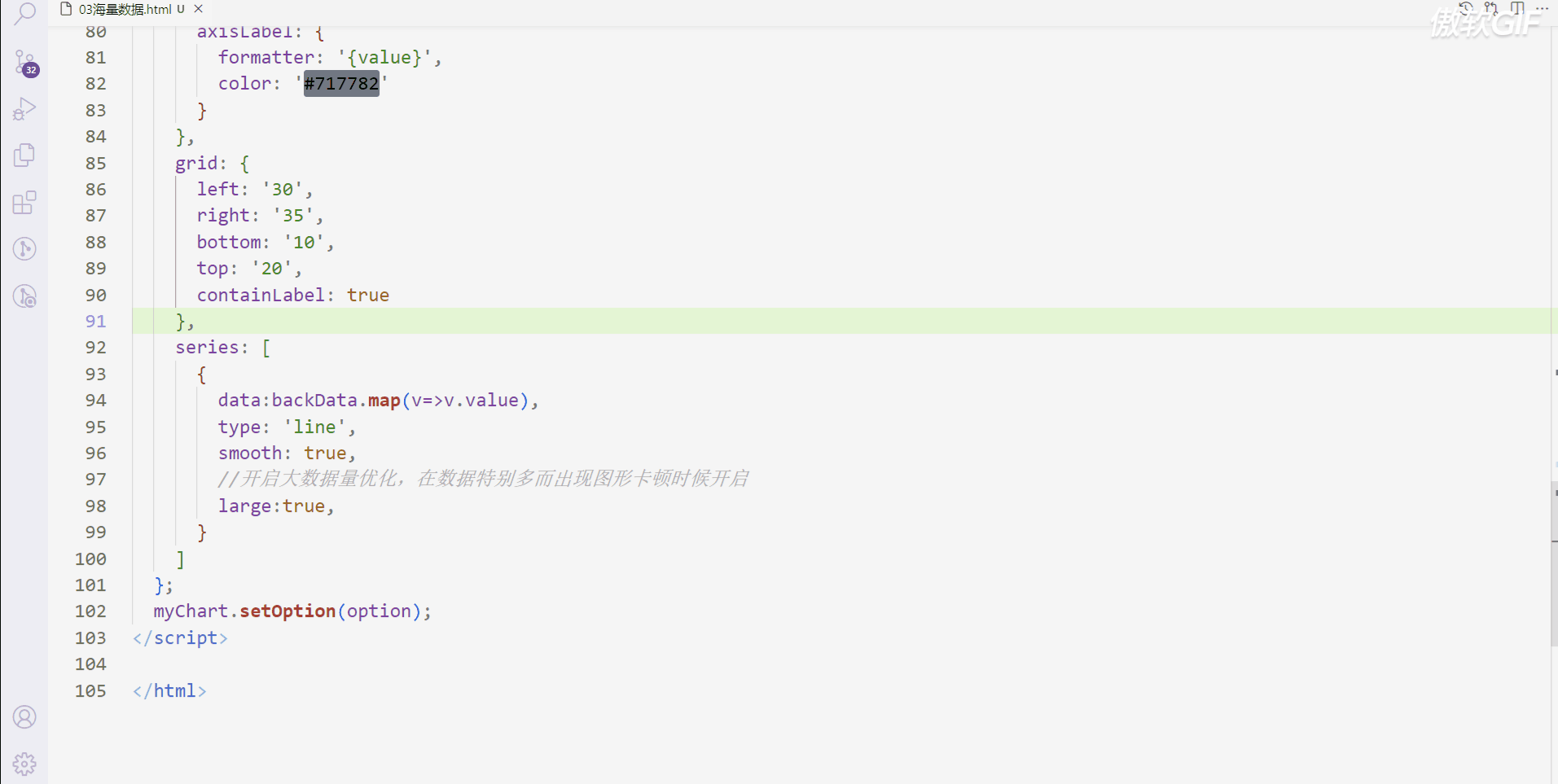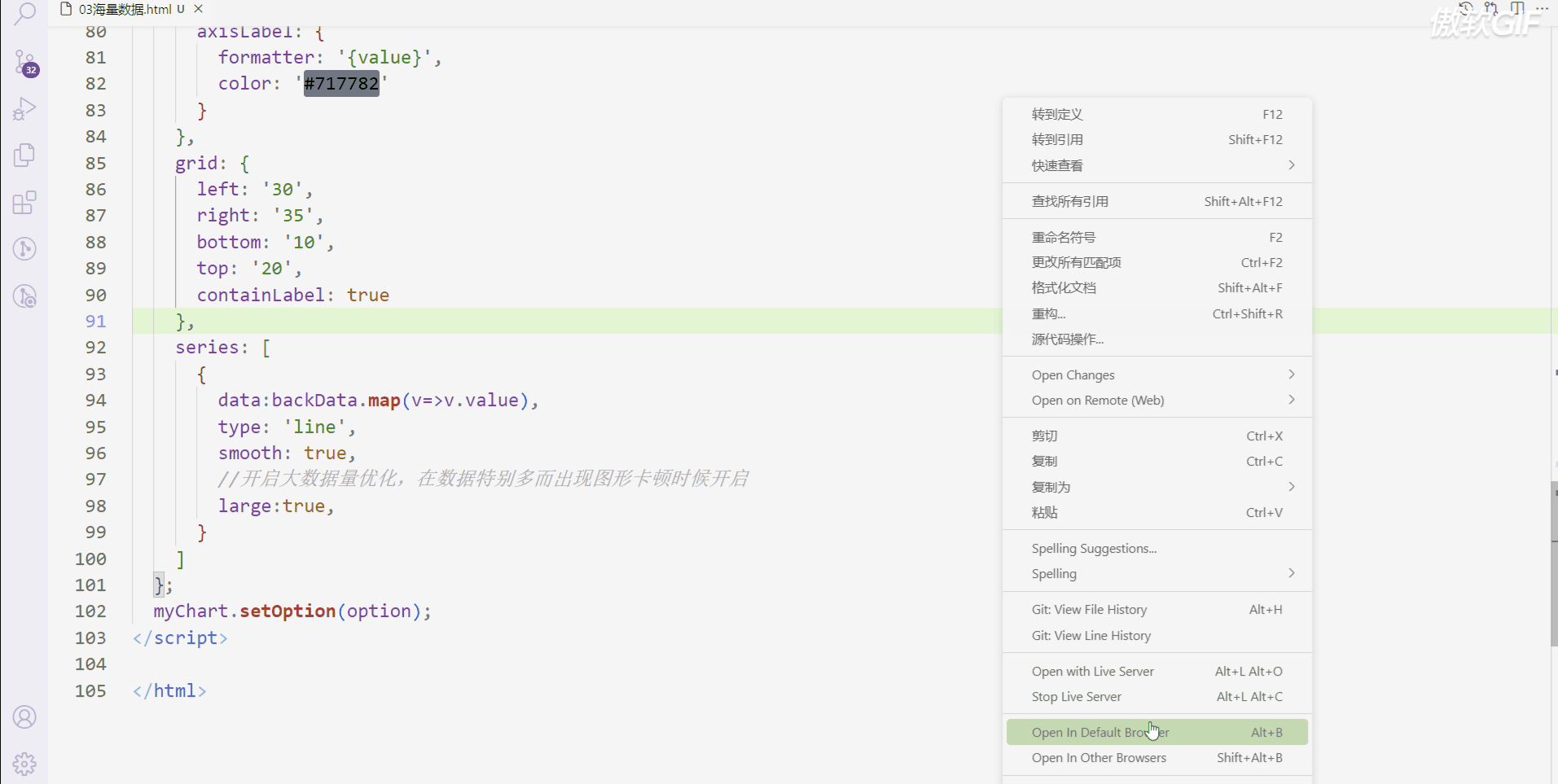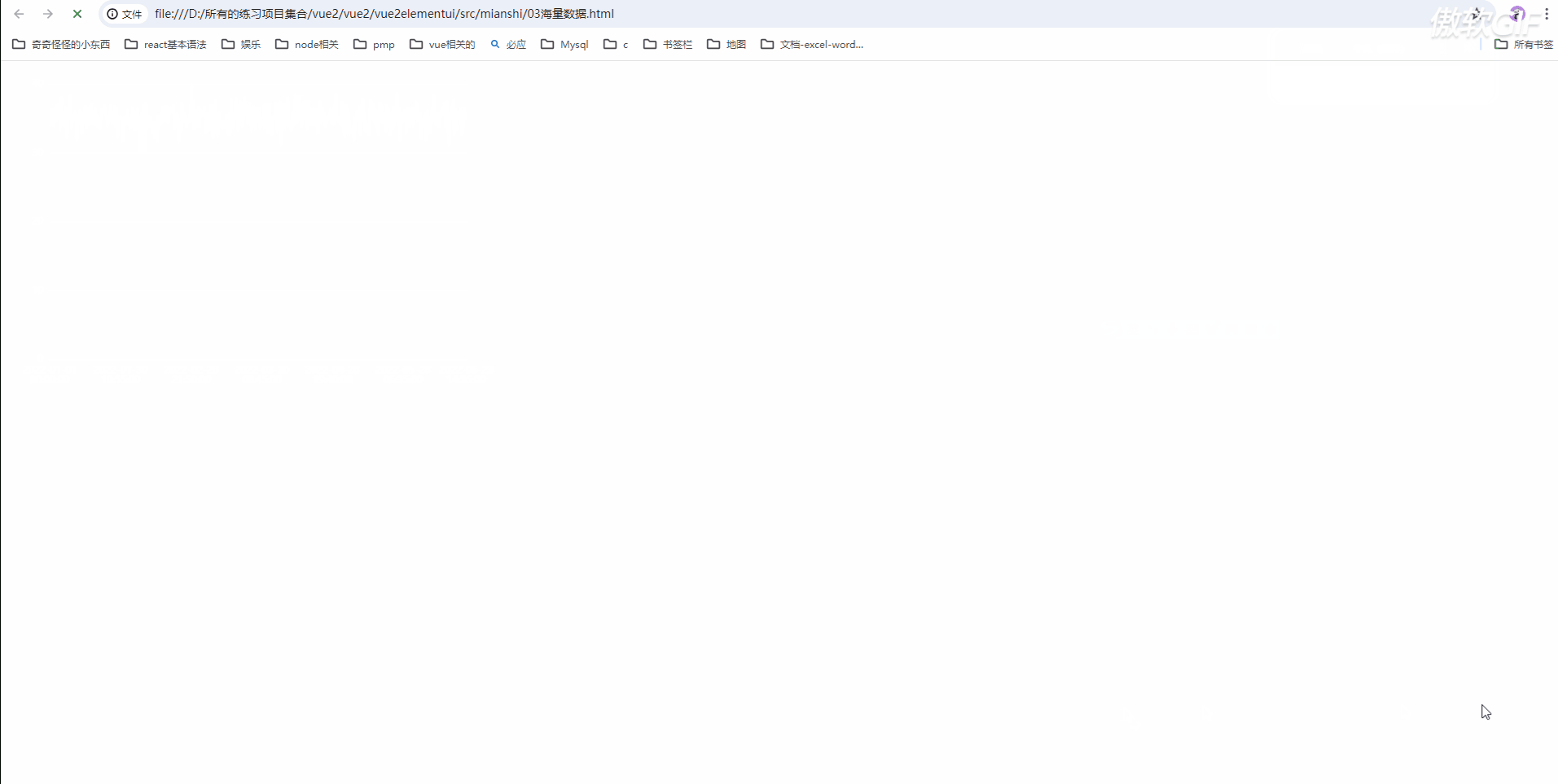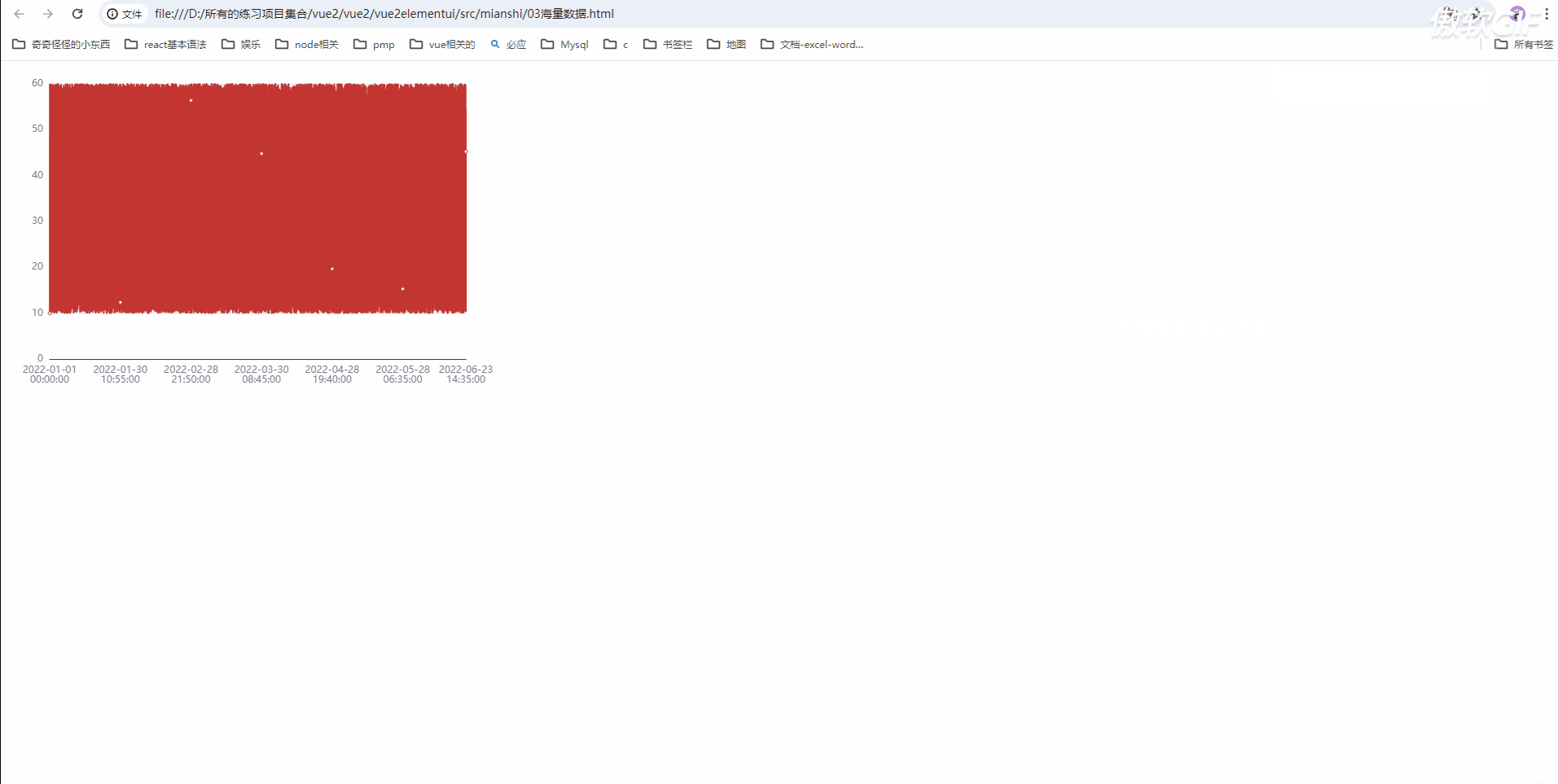
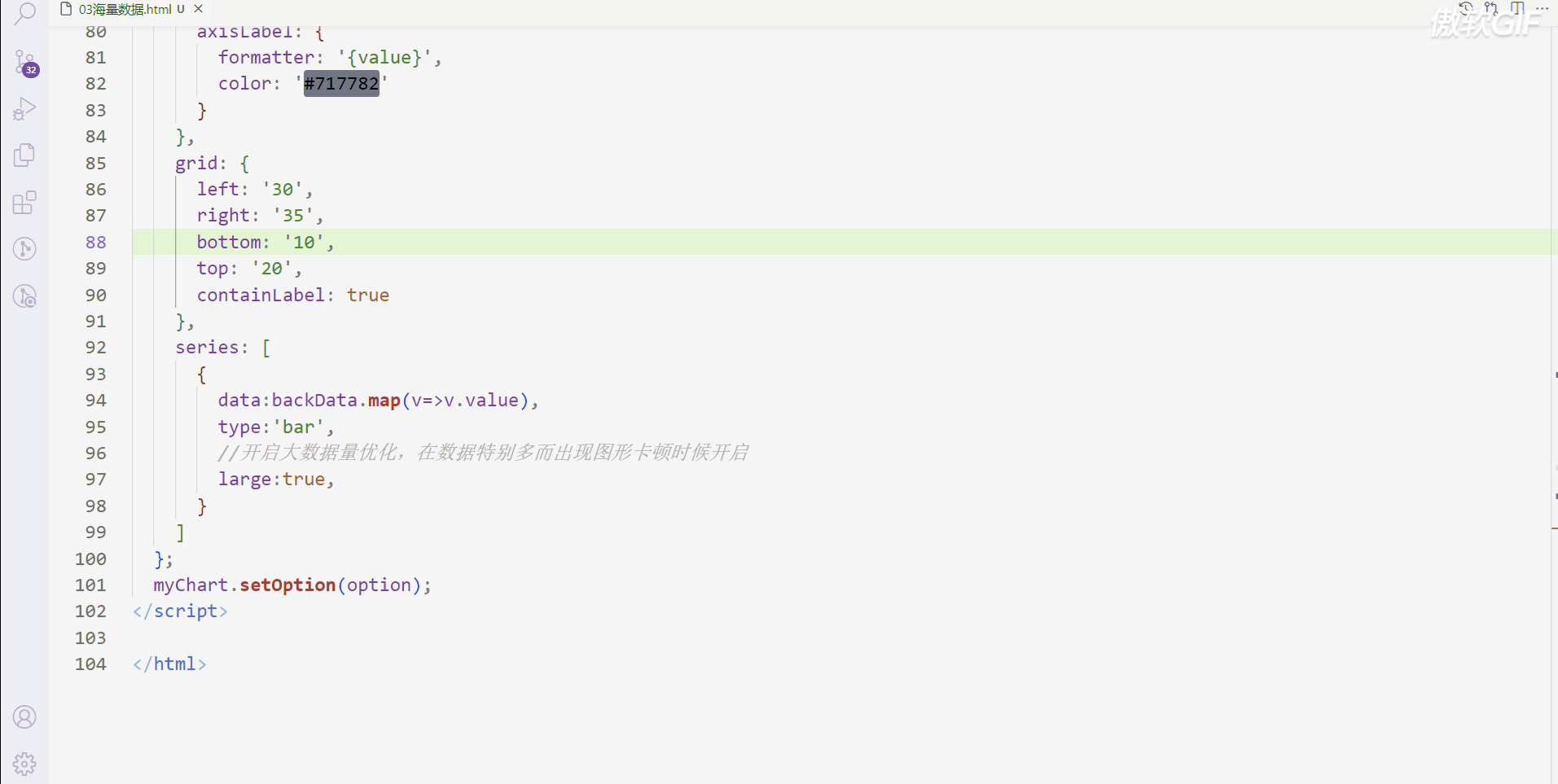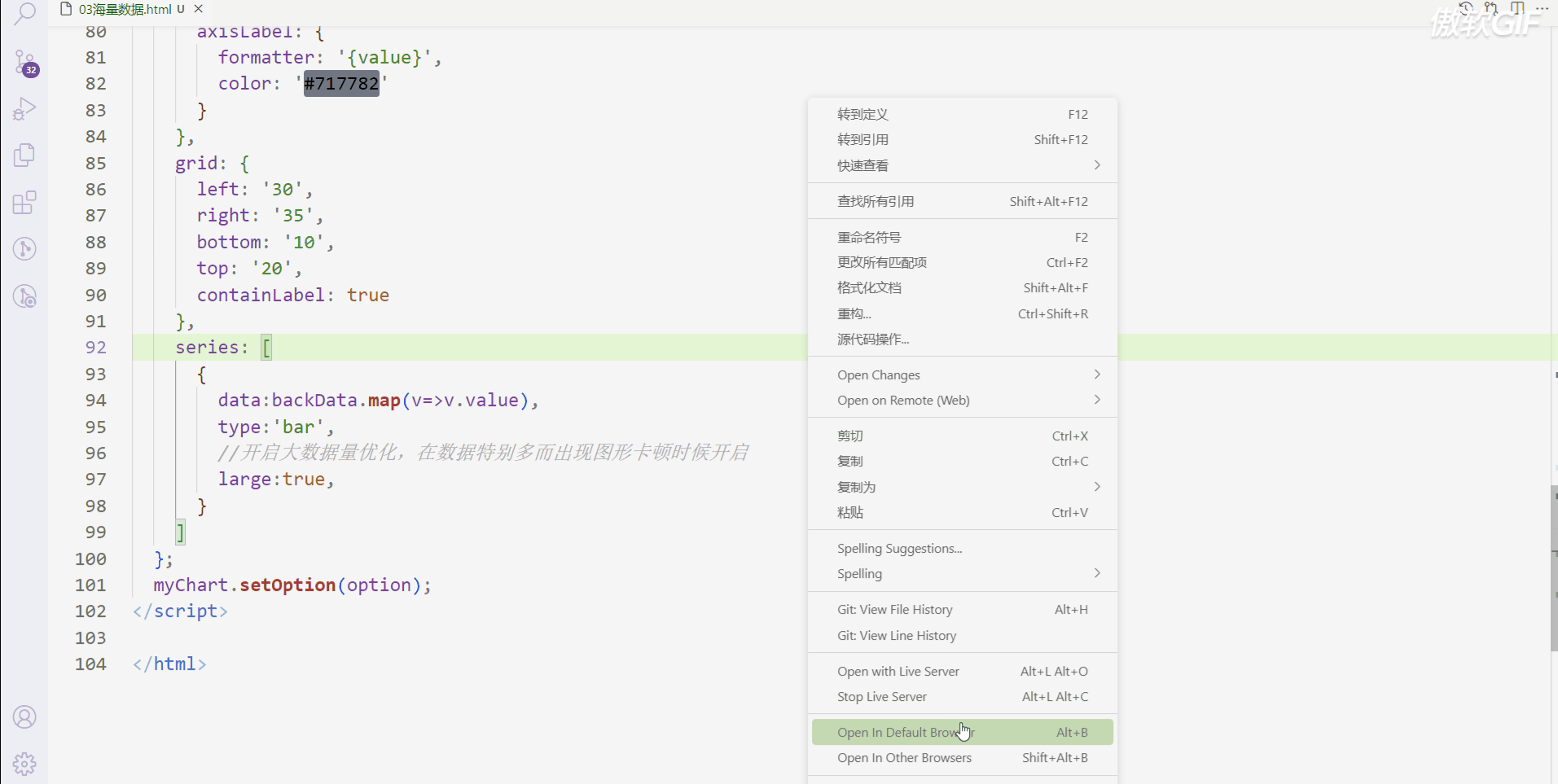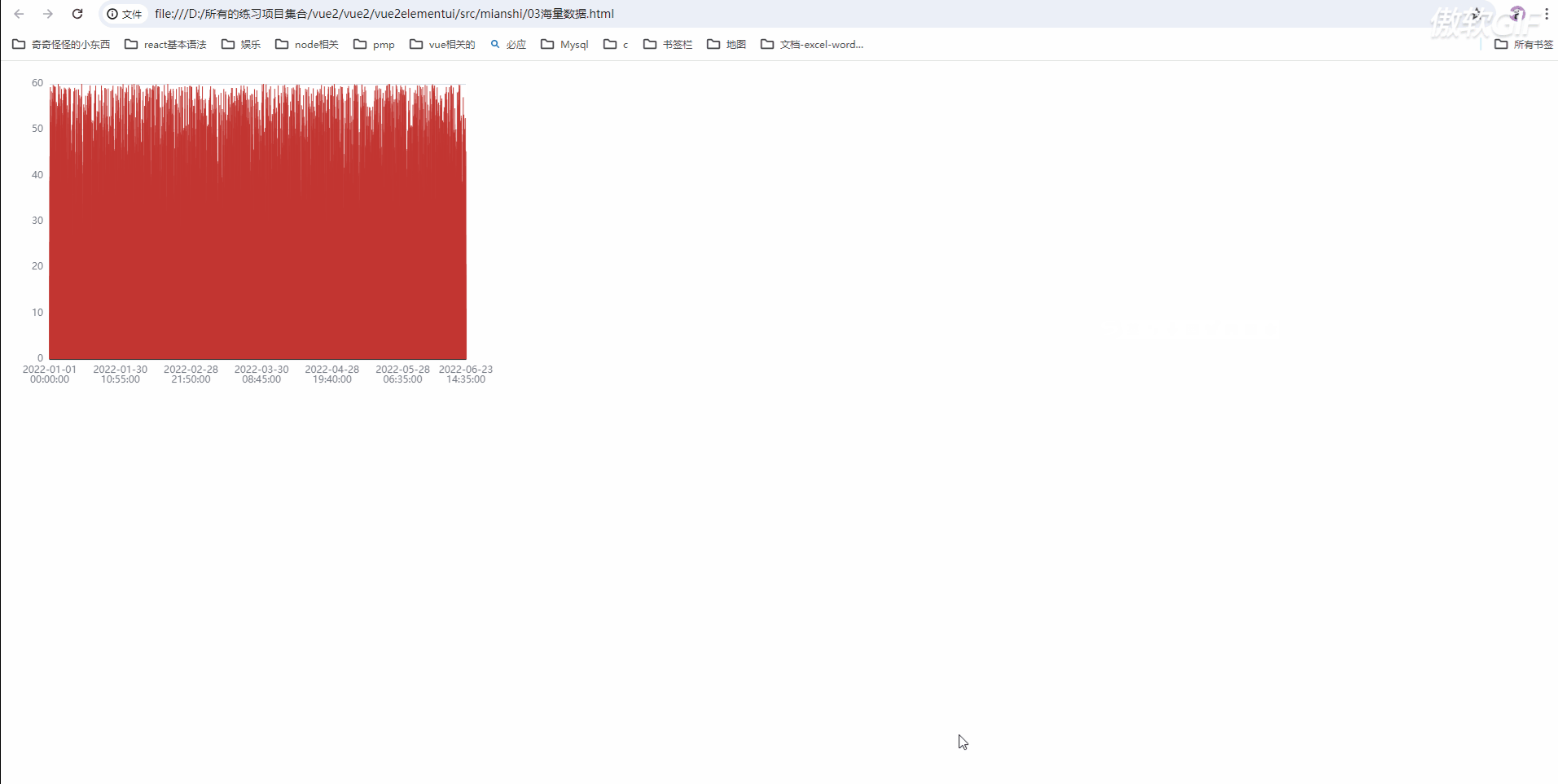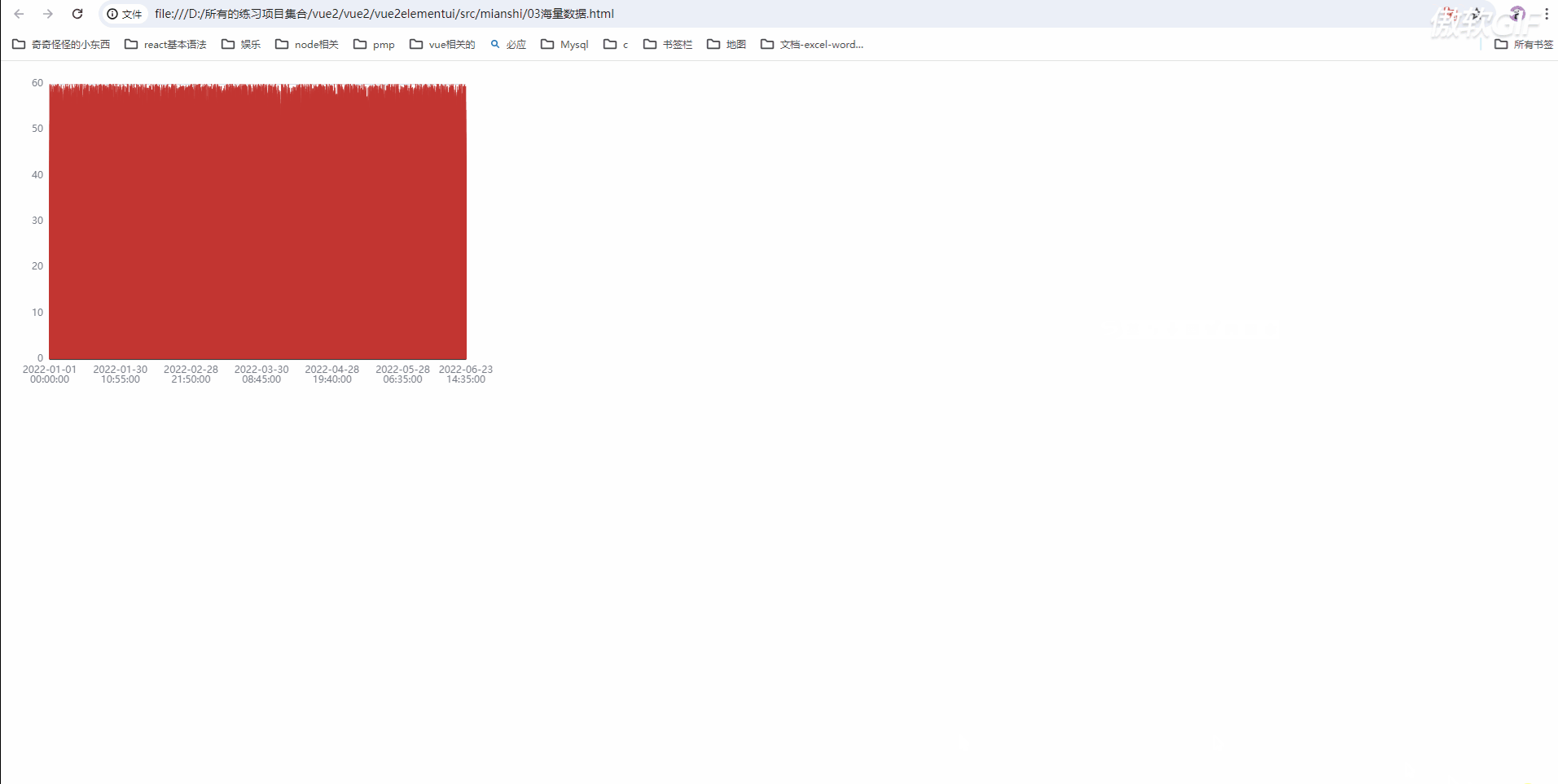
发现使用large属性没有效果
为什么我们使用large没有效果呢?
我们去官网看看怎么说的;
https://echarts.apache.org/zh/option.html#series-bar.type
在上面这个文档中心,我发现折线图[type: 'line']没有 large 属性
large支持的图表:柱状图(bar), K 线图 (candlestick), 路径图(lines),散点图(scatter)
其他类型的图表暂时不支持;
所以我们可以把折线图更改为柱状图看下是否可以解决卡顿问题;
series: [
{
data:backData.map(v=>v.value),
type:'bar',
//开启大数据量优化,在数据特别多而出现图形卡顿时候开启
large:true,
}
]
large 属性的介绍以及优缺点
large:是否开启大数据量优化;
在【数据图形】特别多而出现卡顿时候可以开启。
开启后配合 largeThreshold 在数据量大于指定阈值的时候对绘制进行优化。
优点:解决图形卡数据量大而产生的卡顿问题。
缺点:优化后不能自定义设置单个数据项的样式;
【特别提醒】:
large支持的图表:柱状图(bar), K 线图 (candlestick), 路径图(lines),散点图(scatter)
"辅助"large属性最佳配角 largeThreshold
有些时候;数据量并不是一开始就是大量;
而是经过时间的变化;数据才变成了海量数据;
如果我们一开始就使用large开启优化;这显然是不适合的;
这个时候;我们的最佳配角 largeThreshold 就闪亮登场了;
largeThreshold:开启绘制优化的阈值。
当数据量(即data长度)大于这个阀值的时候,会开启高性能模式。
低于这个阀值;不会开启高性能模式;
比如我们希望:数据量(即data长度)大于1万时开启高性能模式,你可以这样设置:
series: [
{
data:backData.map(v=>v.value),
type:'bar',
//开启大数据量优化,在数据特别多而出现图形卡顿时候开启
large:true,
// 数据量大于1万时开启高性能模式,如果没有大于1万;不会开启
// 此时我们的数据是10万;会开启;渲染非常快
largeThreshold: 10000,
}
]
appendData 属性的简单介绍
根据官网的介绍;
appendData属性会分片加载数据和增量渲染;
在大数据量的场景下(例如地理数的打点);
此时,数据量将会非常的大;
在互联网环境下,往往需要分片加载;
appendData 接口提供了分片加载后增量渲染的能力;
渲染新加入的数据块时,不会清除原有已经渲染的部分数据。
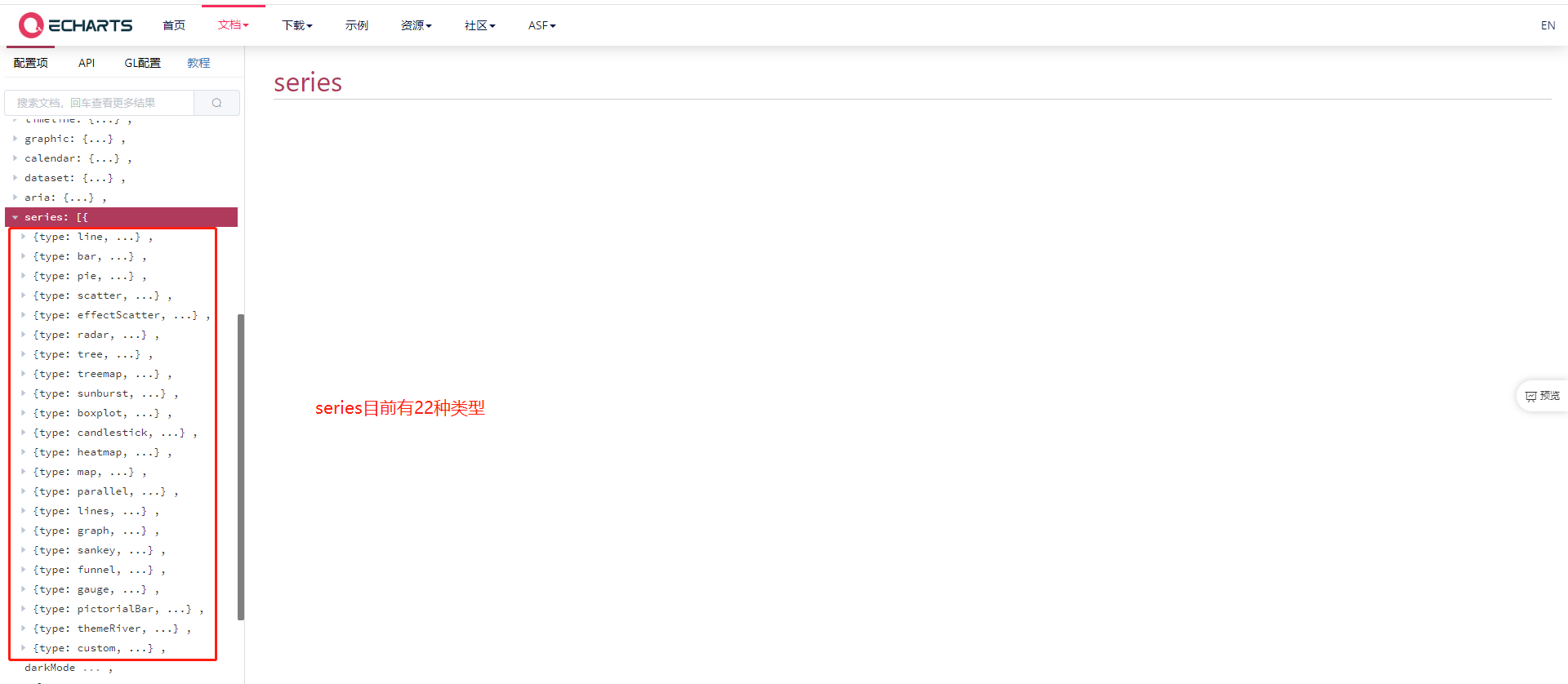
但是并不是所有图表类型都支持这个属性;
目前不支持series系列的;如柱状图,折线图,饼状图这些都不支持;
目前支持的图有: 散点图(scatter),线图(lines)。
ECharts GL的散点图(scatterGL)、线图(linesGL) 和 可视化建筑群(polygons3D)。
上面这段参考:https://echarts.apache.org/zh/api.html#echartsInstance.appendData
series系列的图表
尾声
最近股票亏麻了;哎;好难受;
如果觉得我的文章写的还不错;给我点个推荐;
感谢了
以上就是关于ECharts海量数据渲染解决卡顿的4种方式相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!
暂无评论...












