本文主要讲解关于【大模型】大模型时代的语音合成:音频的离散化表示相关内容,让我们来一起学习下吧!
?文章目录
-
- ?什么是音频离散化
-
- ?音频离散化是什么
- ?SoundStream、Encodec
-
- ? SoundStream
- ?Encodec

?什么是音频离散化
?音频离散化是什么
在自然语言处理(NLP)中,文字是天然的离散特征,譬如我们可以通过维护一个词表,将下面一句话表示成离散的token序列,最终映射到词典对应的 embedding 上:
word_dict = {"大": 0, "模": 1, "型": 2, "时":3, "代": 4, "的": 5, "语": 6, "音": 7, "合": 8, "成": 9}
# sentence
sent = "大模型时代的语音合成"
# tokens
tokens = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
在语音领域,音频的原始表示是连续的音频信号(以时间为一轴的波形图)。通常情况下,我们习惯于选取固定长度的音频信号(窗口),以固定的重叠部分和步长,通过模型编码的方式得到固定维度的向量表示,如下:
# 原始的音频窗口数据
audio_wind_data = [0.14, 0.98, 0.25, ... ...]
# 经过模型 M 卷积后
audio_feature = M(audio_wind_data) # e.g. shape = [256, ]
这种方法虽然做到了音频的向量表示,但未够将音频编码到一个固定的 “词表” 中(通常成为码本,codebook)、进而实现音频的离散化表示(token)。本文将要介绍的方法,即尝试将音频编码为离散化表征,该方法有两大优点:
音频压缩:将连续的特征以离散化的方法近似表示,可以显著减少音频文件的大小;类LLM语音合成模型的前置模块:音频离散化,意味着可以用离散的token序列表征音频,就可以用NLP中的建模思路(特指LLM)来实现语音合成任务。
?SoundStream、Encodec
以下代表性模型,核心思想都围绕 残差矢量量化(RVQ,Residual Vector Quantization),我们先详细介绍 RVQ 的原理,再简要介绍以下工作的异同与特点。
矢量量化(RQ)基于向量近似表征的朴素方法:对于一个原始的向量 v,我们有一个码本(CodeBook)W,码本中有 n个编好序的码本向量 ,我们希望将 v用码本中与之最接近的向量ω 来表示(评估向量相似度的方法有很多,欧式距离、余弦相似度等),这样向量 v 就可以用离散的 token i来表示了,上述方法我们称为矢量量化(RQ)。
RQ 看上去已经能够达到 音频向量离散化表征 的目标了,但这个朴素的方法很难在 表示效果与存储空间 中找到平衡(此处细节非本文讨论的重点,按下不表):
- 希望ω对 v 的描述尽可能准确,则 CodeBook 的向量个数 通常要大到难以接受;
- 想要控制 n 在一个合理的区间,那么 ω 与 v 之间的距离又会比较大,容易造成音频的失真。
残差矢量量化(RVQ,Residual Vector Quantization) 以一种巧妙的 “分层描述” 方法来解决 效果与存储空间 的平衡问题:将量化过程分成多个阶段(与量化器数量有关),每个阶段(或量化器)都有自己的小码本;一个原始的输入向量 v 会先由第一层码本中最近的码本向量(ω,i) 表示,然后计算v 和 (ω,i) 之间的残差(或更直观地称之为误差),交由下一层量化器更精确地表示,以此类推。具体流程如伪码所示:
Input: v0
Quantizers: Q = (q1, q2, ..., qn)
Codebooks: CB = (cb1, cb2, ..., cbn)
cbn = {wn1, wn2, ..., wnm}
v = v0
for i, q in enumerate(Q):
wi = min_dis(v, cbi)
v = v - wi
Output: Q(v) = w1 + w2 + ... + wn
RVQ 的优点包括以下三个方面:
- 较小的码本:每个量化器都只需要近似表示向量、更精确的近似通过逐层传递残差完成,因此每层的码本可以设计得比较小,总码本也远小于传统的 VQ 方式;
- 更高的压缩比:更小的码本意味着需要更少地比特数表达,也就意味着能够在更低的比特率下达到相同的量化精度,因此能够提供更高的压缩比。
- 更高质量的还原效果:RVQ 可以在较低的比特率下达到相同的量化精度。
通常情况下 RVQ 的压缩与还原,需要由 Encoder、Quantizer 和 Decoder 组成的神经网络来实现,他们分别用来做特征编码、矢量量化和音频还原,也即:
- Encoder:将输入的原始音频信号 x,编码为稠密、长度固定的向量 v ;
- Quantizer:使用码本向量,描述向量 v,实现向量的离散化表示;
- Decoder:将离散化表征还原为原始向量、乃至原始的音频信号。
? SoundStream
SoundStream 的功能是提供音频的离散化压缩表示,结构上是一个由编码器、解码器和量化器组成的神经网络,以自监督的方式端到端训练。其中,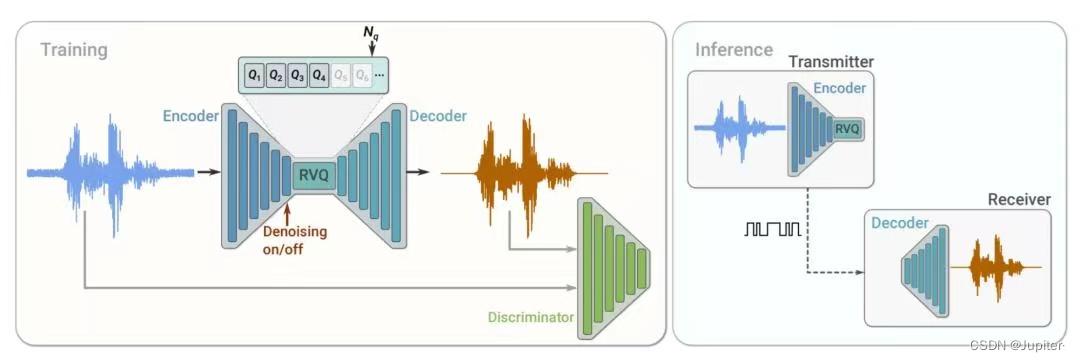
-
编码器 将输入的音频流,转化成 feature sequence;Encoder 部分的结构和 SEANet encoder 一致,但剔除了 skip connection。具体地,由 1 个 1D Conv Layer 和 n 个 EncoderBlock 组成,每一个 Conv block 包含 3 个残差单元和一个 1D 的空洞卷积,最后再接一层 1D Conv Layer。为了确保是可以流式输出的,使用的都是 Casual CNN。
-
量化器: 量化器由conv & residual module组成,量化流程如上文所示。
-
解码器: 将离散 tokens 还原成音频流。1 个 Conv Layer + n DecoderBlock 组成,其中 DecoderBlock 相当于是 EncoderBlock 的逆操作,由 1 个反卷积接 3 个 residual unit 做上采样,最后再接 1 个 卷积层。
-
其它 SoundStream 在训练的过程中,采用 1)重构损失(语谱) 和 2)对抗训练损失 对模型进行优化。对抗训练中的 Discriminator 的输入是真实音频与解码器还原的音频;
伪码如下:
?Encodec
整体结构与 SoundStream 相似,encoder-decoder支持 streaming & non-streaming 两种推理方式;Quantizer 的 base module 替换成了 transformer,其中第一层量化器是自回归结构(NAR),后续的量化器是非自回归结构(AR);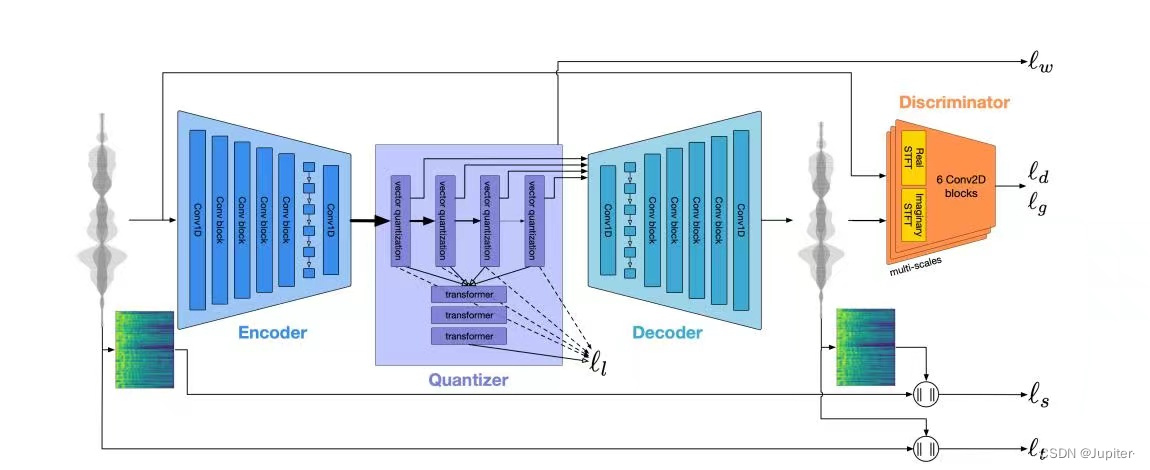
在损失函数上,除了 1)mel语谱重构损失 和 2)对抗损失,增加了 3)VQ commitment 损失(针对 encoder 的output 及其量化后的 features 的距离),从而提升量化器对向量描述的效果: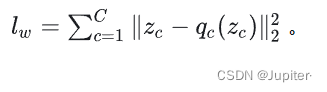
最后,作者引入了 encoder-decoder 结构中很常见的 Language Model,用于提前预测下一时刻的离散特征;该模块在提高编解码速度的同时,音频表示效果并没有明显降低,这也从侧面验证了利用 LLM 的范式解决语音合成问题的可行性(离散化表示后,万物皆可"生成")。
以上就是关于【大模型】大模型时代的语音合成:音频的离散化表示相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!











