本文主要讲解关于Spark-机器学习(4)回归学习之逻辑回归相关内容,让我们来一起学习下吧!
在之前的文章中,我们来学习我们回归中的线性回归,了解了它的算法,知道了它的用法,并带来了简单案例。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-机器学习(3)回归学习之线性回归-CSDN博客文章浏览阅读1.4k次,点赞39次,收藏28次。今天的文章,我们来学习我们回归中的线性回归,希望大家能有所收获。同时,希望我的文章能帮助到每一个正在学习的你们。也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/138014891今天的文章,我们来学习我们回归中的逻辑回归,并带来简单案例,学习用法。希望大家能有所收获。
目录
一、逻辑回归
什么是逻辑回归?
spark线性回归
二、示例代码
拓展-逻辑回归算法介绍及用法
一、逻辑回归
什么是逻辑回归?
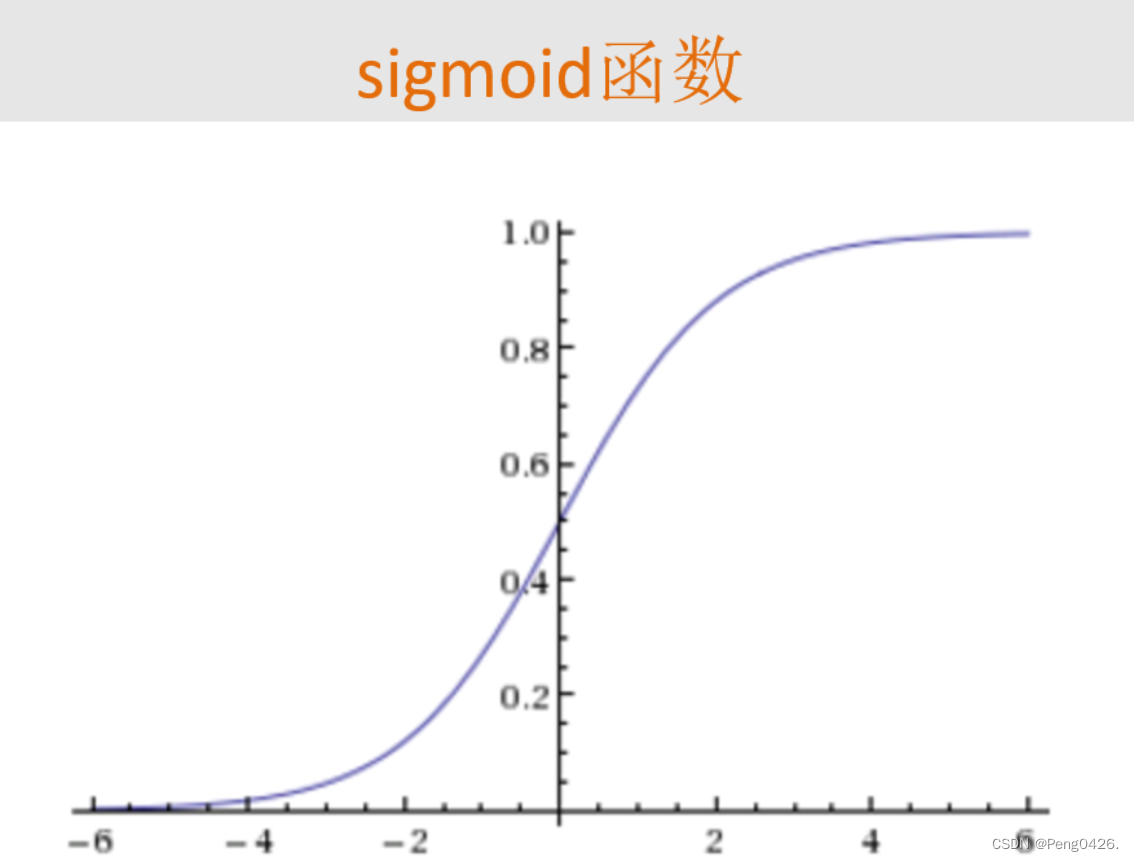
逻辑回归sigmoid函数
逻辑回归(Logistic Regression)是一种广义的线性回归分析模型,它主要用于解决二分类(0或1)问题,也可以用于多分类问题。逻辑回归的名称中虽然有“回归”二字,但它实际上是一种分类方法,主要用于研究某些事件发生的概率。
逻辑回归通过sigmoid函数将线性回归模型的输出映射到(0,1)之间,从而得到某个事件发生的概率。sigmoid函数的形式为:
g(z) = 1 / (1 + e^(-z))
其中,z是线性回归模型的输出。通过sigmoid函数,我们可以将线性回归模型的输出转化为一个概率值,从而进行二分类或多分类。
逻辑回归的优点包括计算代价不高,易于理解和实现。然而,它也有一些缺点,例如对数据和场景的适应能力有局限性,有时候不如决策树算法准确率高。另外,逻辑回归假设数据服从伯努利分布,因此不适合处理具有多个离散值的问题。
逻辑回归是一种常用的分类算法,尤其适用于二分类问题。在实际应用中,我们需要根据具体的问题和数据特点来选择合适的算法。
spark线性回归
Spark线性回归是利用Spark平台实现的一种线性回归分析方法。线性回归是一种回归分析,它使用称为线性回归方程的最小平方函数来对一个或多个自变量和因变量之间的关系进行建模。这种函数是回归系数的线性组合,其中回归系数是模型的参数。在Spark中,线性回归可以通过其机器学习库MLlib来实现,该库提供了用于数据分析和机器学习的各种算法和工具。通过Spark线性回归,用户可以处理大规模的数据集,并利用分布式计算的能力来加速模型的训练和预测过程。Spark线性回归在数据科学、机器学习、统计分析等领域有广泛的应用。
二、示例代码
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.sql.SparkSession
object p4 {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark = SparkSession
.builder()
.appName("LogisticRegression")
.master("local")
.getOrCreate()
import spark.implicits._
// 加载CSV文件
val data = spark.read.option("header", "true").csv("C:\IDEA\P1\p1\data01.csv")
// 假设features列只包含一个double类型的值,直接转换即可
.withColumn("features", $"features".cast("double"))
// 选择包含label和features的列
val finalData = data.select("label", "features")
// 划分训练集和测试集
val Array(trainingData, testData) = finalData.randomSplit(Array(0.7, 0.3))
// 创建逻辑回归模型
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
// 训练模型
val lrModel = lr.fit(trainingData)
// 在测试集上进行预测
val predictions = lrModel.transform(testData)
// 选择 (prediction, true label) 并展示结果
predictions.select("prediction", "label").show(10)
// 计算准确率
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println(s"Test Accuracy = $accuracy")
}
}代码的主要步骤如下:
-
创建一个
SparkSession对象,这是使用Spark MLlib进行数据处理和模型训练的入口点。 -
读取一个CSV文件作为数据集,假设该数据集包含"label"和"features"两列,其中"label"是目标变量,而"features"是特征变量。
-
将"features"列的数据类型转换为
double,因为逻辑回归通常需要数值型特征。 -
从数据集中选择"label"和"features"列,得到一个新的DataFrame,用于后续的模型训练和评估。
-
将数据集划分为训练集和测试集,比例分别为70%和30%。
-
创建一个
LogisticRegression对象,并设置最大迭代次数和正则化参数。 -
使用训练数据拟合逻辑回归模型。
-
使用训练好的模型对测试集进行预测。
-
展示预测结果中的前10条记录,包括预测值和真实标签。
-
使用
MulticlassClassificationEvaluator计算测试集的准确率。 -
打印出测试集的准确率。
拓展-逻辑回归算法介绍及用法
| 方法/算法 | 关键字 | 描述 | 示例 |
|---|---|---|---|
| 二项逻辑回归 | binomial logistic regression | 用于预测二元结果,即输出结果为两个类别之一。 | 使用Spark MLlib的LogisticRegression类,设置family参数为binomial来进行二项逻辑回归。 |
| 多项逻辑回归 | multinomial logistic regression | 用于预测多类结果,即输出结果为多个类别之一。 | 使用Spark MLlib的LogisticRegression类,设置family参数为multinomial来进行多项逻辑回归。 |
| 随机梯度下降(SGD) | stochastic gradient descent | 一种优化算法,用于最小化逻辑回归的损失函数。 | 在Spark MLlib中,可以通过设置solver参数为sgd来使用随机梯度下降优化算法。 |
| L-BFGS | L-BFGS | 一种准牛顿法优化算法,用于快速求解大规模优化问题。 | 在Spark MLlib中,可以通过设置solver参数为lbfgs来使用L-BFGS优化算法。 |
| 弹性网络正则化 | elastic net regularization | 结合了L1和L2正则化,用于防止过拟合。 | 在Spark MLlib的LogisticRegression类中,通过设置elasticNetParam参数来调整L1和L2正则化的权重。 |
以上就是关于Spark-机器学习(4)回归学习之逻辑回归相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!












