本文主要讲解关于神经网络的激活函数相关内容,让我们来一起学习下吧!

目录
神经网络
激活函数
sigmoid 激活函数
tanh 激活函数
backward方法
relu 激活函数
softmax 激活函数
神经网络
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的 计算模型。人脑可以看做是一个生物神经网络,由众多的神经元连接而成。各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通过轴突输出信号。

人工神经网络

每一个神经元都是=g(w1x1 + w2x2 + w3x3...) ,即先对输入求和,再对其激活
💎这个流程就像,来源不同树突(树突都会有不同的权重)的信息, 进行的加权计算, 输入到细胞中做加和,再通过激活函数输出细胞值。我们使用多个神经元来构建神经网络,相邻层之间的神经元相互连接,并给每一个连接分配一个强度 w,机器学习的目的就是求这些 w 值。
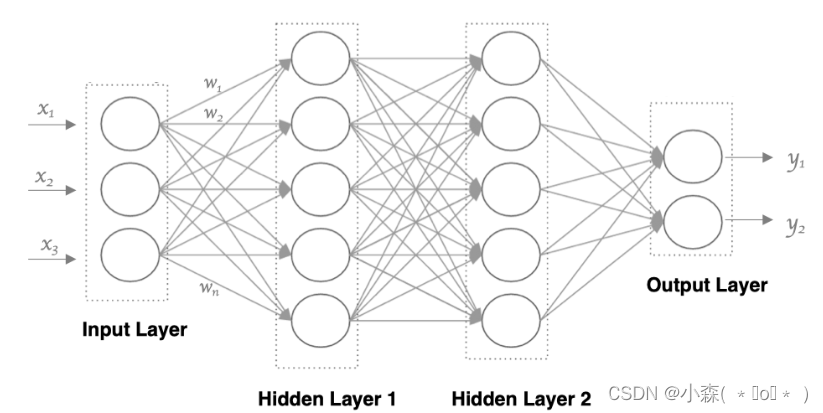
- 输入层: 即输入 x 的那一层
- 输出层: 即输出 y 的那一层
- 隐藏层: 输入层和输出层之间都是隐藏层
激活函数
💎激活函数用于对每层的输出数据进行变换, 进而为整个网络结构结构注入了非线性因素。此时, 神经网络就可以拟合各种曲线。如果不使用激活函数,整个网络虽然看起来复杂,其本质还相当于一种线性模型。
假设有一个单层的神经网络,其输入为𝑥x,权重为𝑤w,偏置为𝑏b,那么该层的输出𝑦y可以表示为:𝑦=𝑤⋅𝑥+𝑏y=w⋅x+b
对于多层的神经网络,如果每一层都不使用激活函数,那么无论网络有多少层,最终的输出都可以表示为输入𝑥x的一个线性组合 y=wn⋅(wn−1⋅(…(w2⋅(w1⋅x+b1)+b2)…)+bn−1)+bn
通过给网络输出增加激活函数, 实现引入非线性因素, 使得网络模型可以逼近任意函数。
激活函数能够向神经网络引入非线性因素,使得网络可以拟合各种曲线。没有激活函数时,无论神经网络有多少层,其输出都是输入的线性组合,这样的网络称为感知机,它只能解决线性可分问题,无法处理非线性问题。
增加激活函数之后, 对于线性不可分的场景,神经网络的拟合能力更强:
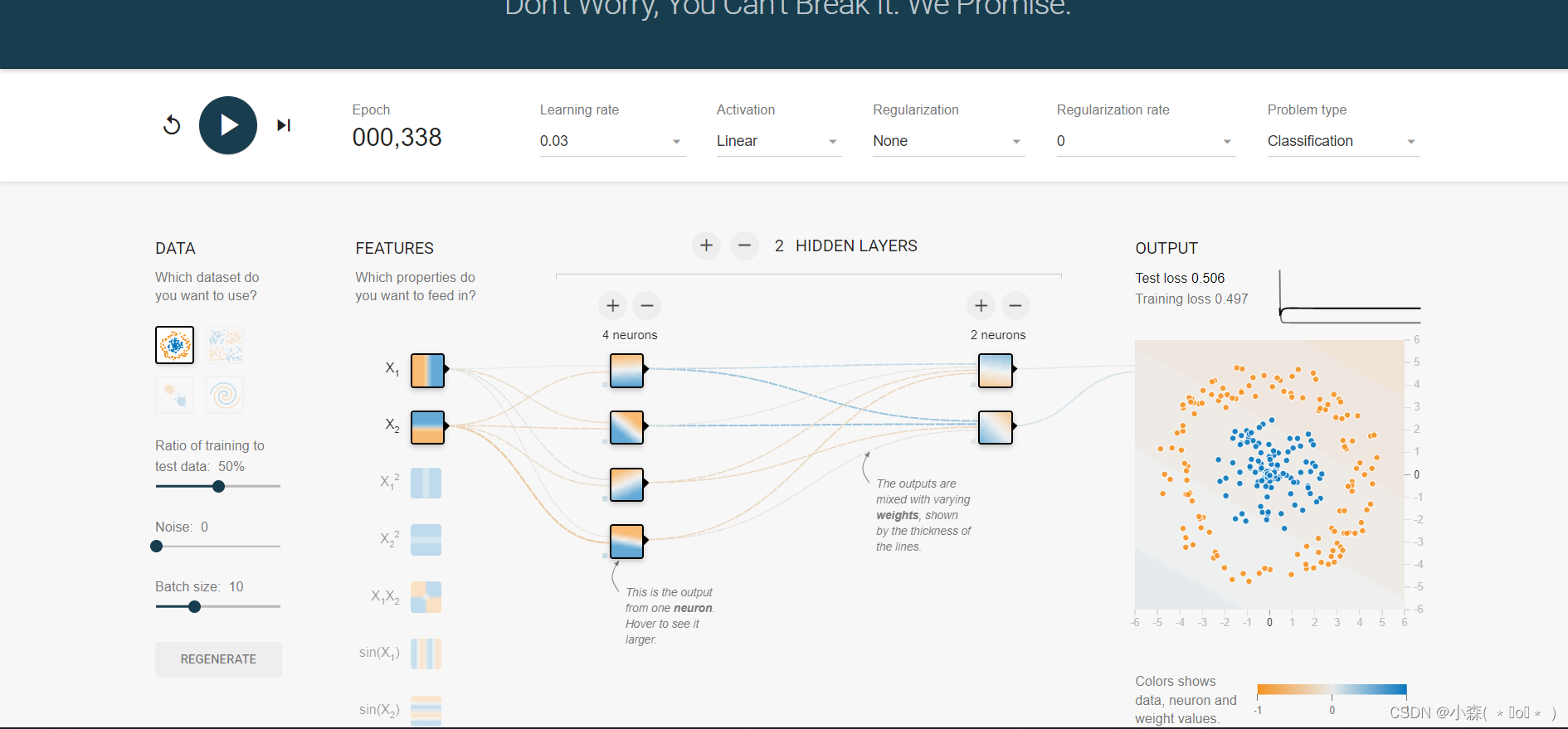
🔎我们可以发现如果只使用线性函数Lnear,则模型永远不会区分两种小球(不管多少次Epochs)
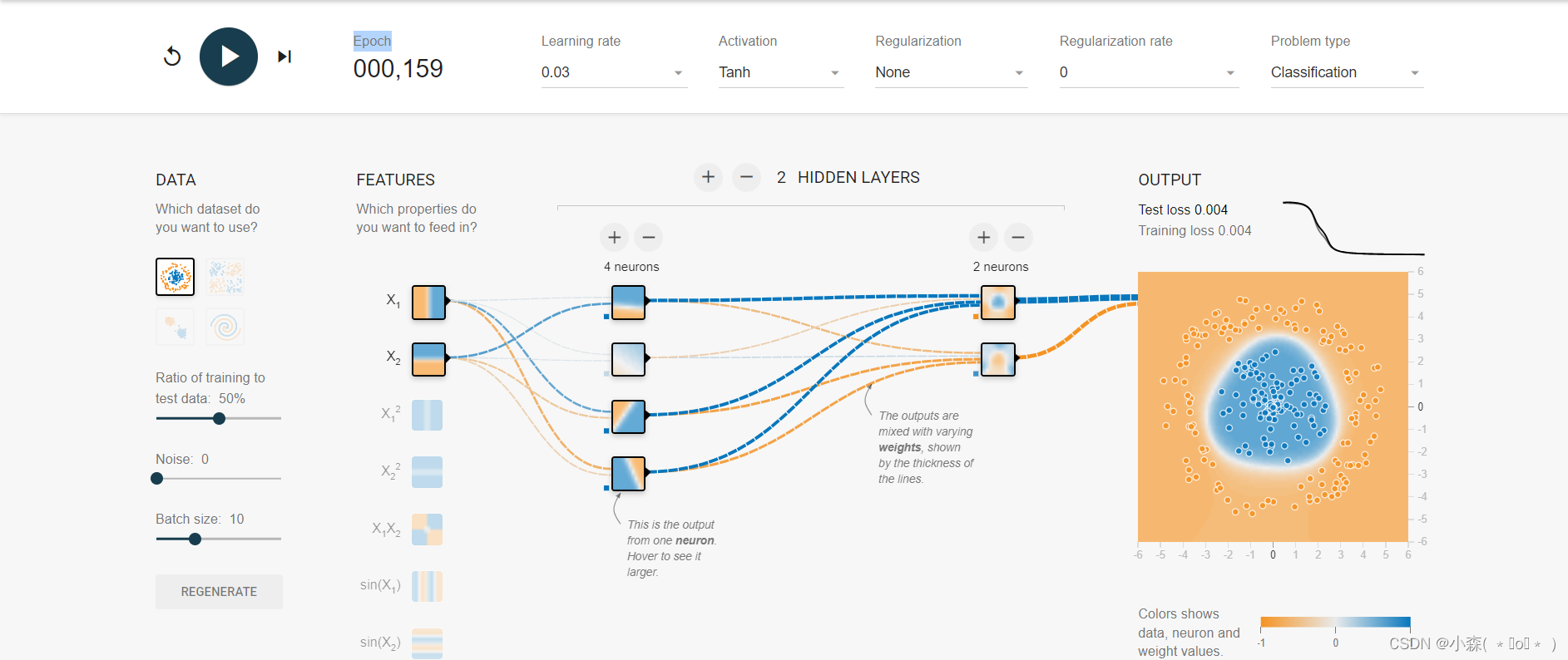
🔎但当我们引入非线性激活函数后,仅仅100次就可以完美区分两种小球。
激活函数主要用来向神经网络中加入非线性因素,以解决线性模型表达能力不足的问题,它对神经网络有着极其重要的作用。我们的网络参数在更新时,使用的反向传播算法(BP),这就要求我们的激活函数必须可微。
sigmoid 激活函数
f(x) = 1 / (1 + e^(-x))。
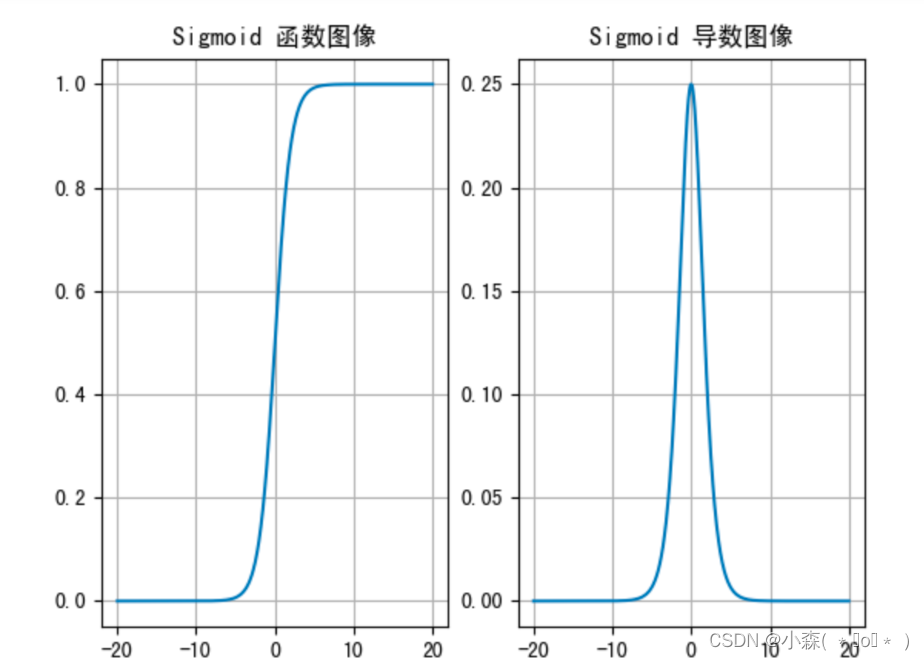
Sigmoid函数,也称为逻辑斯蒂激活函数,是早期神经网络中最常用的激活函数之一。它的特点是能够将任何实数值映射到介于0和1之间的值,这使得它在二分类问题中尤其有用,可以将输出解释为概率或者激活程度。
这个函数的图形呈现出一个S形曲线,它在中心点(x=0)增长缓慢,而在两端则增长迅速接近水平。这种特性使得Sigmoid函数在早期的神经网络中非常受欢迎,因为它可以帮助网络学习非线性关系。然而,它也存在梯度消失的问题,这意味着在训练过程中,当输入值非常大或非常小的时候,梯度几乎为零,这会导致权重更新变得非常缓慢,从而影响网络的学习效率。
一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的,所以在实践中这种激活函数使用的很少。sigmoid函数一般只用于二分类的输出层。
📀绘制Sigmoid函数图像
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
def test():
_, axes = plt.subplots(1, 2)
x = torch.linspace(-20, 20, 1000)
y = F.tanh(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Sigmoid 函数图像')
x = torch.linspace(-20, 20, 1000, requires_grad=True)
torch.sigmoid(x).sum().backward()
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title('Sigmoid 导数图像')
plt.show()
if __name__ == '__main__':
test()📀在神经网络中,一个神经元的输出可以通过Sigmoid函数来表示其被激活的概率,接近1的值表示高度激活,而接近0的值则表示低激活。这种特性使得Sigmoid函数特别适合用于二分类问题的输出层,因为它可以表示两个类别的概率分布。
tanh 激活函数

Tanh 的函数图像、导数图像 :

Tanh 函数将输入映射到 (-1, 1) 之间,图像以 0 为中心,在 0 点对称,当输入 大概<-3 或者 >3 时将被映射为 -1 或者 1。与 Sigmoid 相比,它是以 0 为中心的,使得其收敛速度要比 Sigmoid 快,减少迭代次数。然而,从图中可以看出,Tanh 两侧的导数也为 0,同样会造成梯度消失。
- 💡由于tanh函数的输出均值是0,这与许多样本数据的分布均值相近,因此在训练过程中,权重和偏差的更新可以更快地接近最优值。
- 💡tanh函数的导数在0到1之间变化,而Sigmoid函数的导数最大值仅为0.25,这意味着在反向传播过程中,tanh函数能够提供相对较大的梯度,从而减缓梯度消失的问题,有助于网络更快地收敛。
- 💡由于tanh函数的对称性和输出范围,它在正向传播时能够更好地处理正负输入值,这有助于在反向传播时进行更有效的权重更新,减少迭代次数。
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
def test():
_, axes = plt.subplots(1, 2)
# 函数图像
x = torch.linspace(-20, 20, 1000)
y = F.tanh(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Tanh 函数图像')
# 导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
F.tanh(x).sum().backward()
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title('Tanh 导数图像')
plt.show()
🔎F.tanh(x)计算了输入张量x的tanh值,然后.sum()将这些tanh值相加得到一个标量值。接下来,.backward()方法会计算这个标量值关于输入张量x的梯度,即tanh函数的导数。这样,我们就可以得到tanh函数在每个输入点上的导数值,从而绘制出tanh导数图像。
backward方法
- 通用性:
backward()方法不限于计算损失函数的梯度,它可以用于任何需要进行梯度计算的张量。例如,如果你在进行一些非神经网络的任务,比如简单的数学运算,你也可以使用backward()来计算梯度。- 要使用
backward()计算梯度,必须满足几个条件。首先,需要计算梯度的张量必须是叶子节点,即它们不是任何其他张量的计算结果。其次,这些张量必须设置requires_grad=True以表明需要跟踪它们的梯度。最后,所有依赖于这些叶子节点的张量也必须设置requires_grad=True,以确保梯度可以传播到整个计算图中。
relu 激活函数
ReLU激活函数的公式是 ReLU(x)=max(0, x)。
ReLU激活函数(Rectified Linear Unit)在神经网络中用于引入非线性特性,其特点是计算简单且能够加速训练过程。对于正值,它直接输出输入值(即 𝑓(𝑥)=𝑥f(x)=x),对于负值,输出为零(即 𝑓(𝑥)=0f(x)=0)。这种简单的阈值操作避免了复杂的指数或乘法运算,从而显著减少了计算量。
由于ReLU在正值区间内具有不变的梯度(即梯度为1),它有助于维持信号的传播,使得基于梯度的优化算法(如SGD、Adam等)能够更有效地更新网络权重。
函数图像如下:
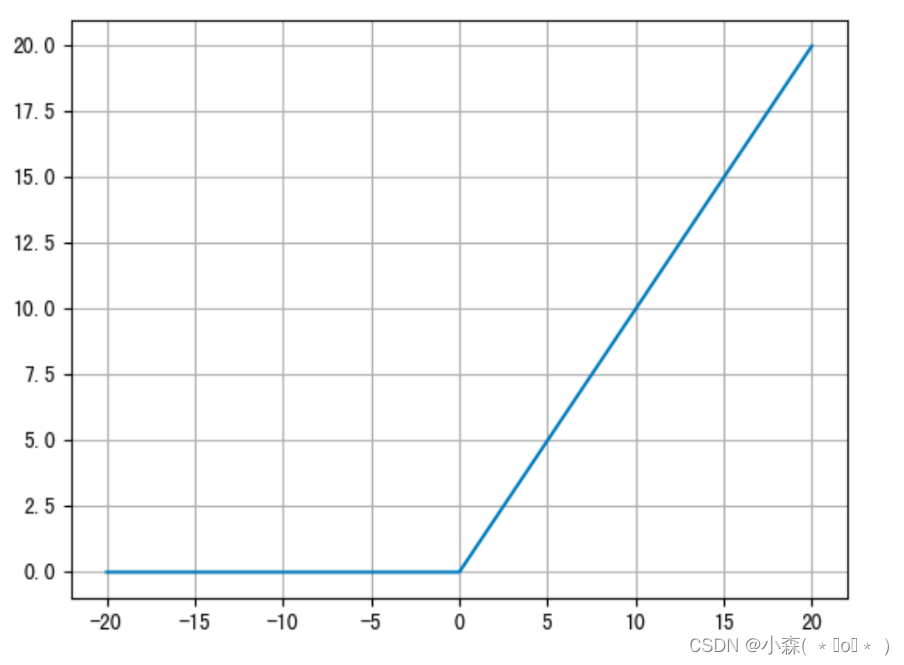
ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新。
与sigmoid相比,RELU的优势是:
采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。 sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。 Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
在神经网络的前向传播过程中,每个隐藏层的神经元都会对其输入执行线性变换(通过权重和偏差),然后应用激活函数。例如,一个神经元的输出y可以通过以下方式计算 y=ReLU(W^Tx+b),其中W是权重矩阵,x是输入向量,b是偏置项。
在前向传播后,如果输出与实际值存在差距,则使用反向传播算法根据误差来更新网络中的权重和偏差。这个过程中,ReLU函数的梯度(导数)也会被计算出来,用于调整连接权重。
softmax 激活函数
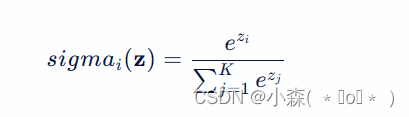
这里,( K ) 是类别的总数,( e ) 是自然对数的底数(约等于2.71828)。
softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。 SoftMax 函数将每个输入元素 ( z_i ) 映射到 (0,1) 区间内,并且所有输出值的总和为1,这使它成为一个有效的概率分布。
Softmax 直白来说就是将网络输出的 logits 通过 softmax 函数,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们将它理解成概率,选取概率最大(也就是值对应最大的)节点,作为我们的预测目标类别。
import torch
scores = torch.tensor([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75])
probabilities = torch.softmax(scores, dim=0)
print(probabilities)
# 结果:tensor([0.0212, 0.0177, 0.0202, 0.0202, 0.0638, 0.0287, 0.0185, 0.0522, 0.0183,
0.7392])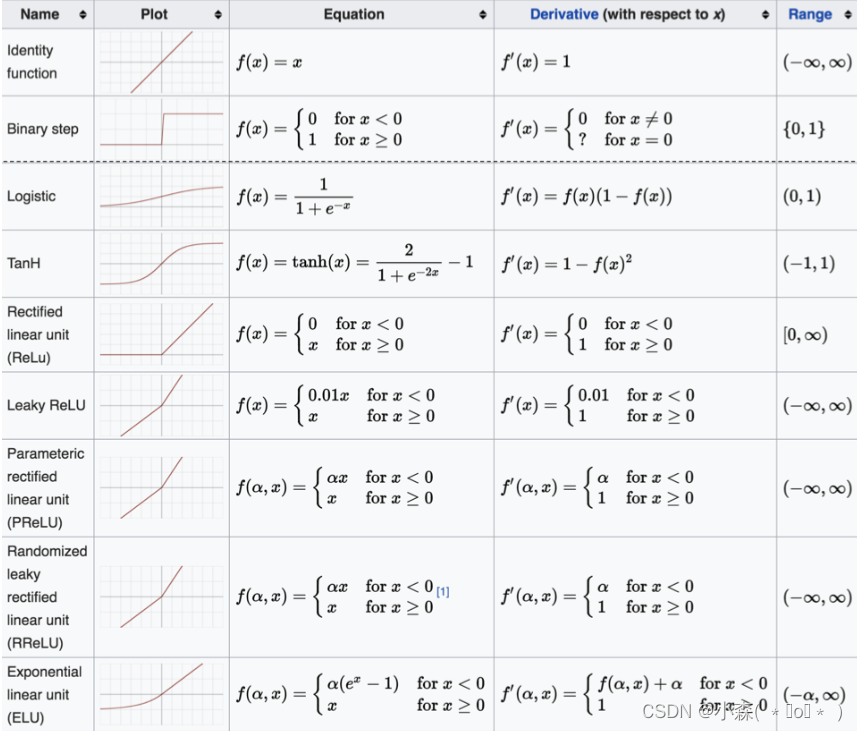
🍳对于隐藏层:
-
优先选择RELU激活函数
-
如果ReLu效果不好,那么尝试其他激活,如Leaky ReLu等。
-
如果你使用了Relu, 需要注意一下Dead Relu问题, 避免出现大的梯度从而导致过多的神经元死亡。
-
不要使用sigmoid激活函数,可以尝试使用tanh激活函数
🍳对于输出层:
-
二分类问题选择sigmoid激活函数
-
多分类问题选择softmax激活函数
-
回归问题选择identity激活函数
以上就是关于神经网络的激活函数相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!












