本文主要讲解关于大历史下的 tcp:一个松弛的传输协议相关内容,让我们来一起学习下吧!
如果 tcp 是一个相对松弛的协议,会发生什么。
所谓松弛感,意思是它允许 “漏洞”,允许可靠传输的不封闭,大致就是:“不求 100% 可靠,只要 90%(或多或少) 可靠,另外 10% 的错误可检测到” or “不实现 100% 可靠逻辑,只负责 99%(或多或少) 大概率事件,忽略 1% 的小概率事件,由上层协议处理或不处理”。
前文谈到 tcp timewait,我说只需一个按连接递增的 16bit 全局 version option 就能不用 timewait 和 timestamps 而解决 segment 归属问题,timewait 可以直接取消,timestamps 另作他用。如此可卸载大量复杂性。
这题还有更松弛的解法,比如为每个连接随机生成一个 16bit 标识,或用当前时间生成一个摘要作为 tcp option 替代全局递增 version 做连接区分。如果没有松弛理念,经理肯定会说 “16bit 容易碰撞,要么你用 32bit 或 64bit?”,但相反的问题拉僵了他也考虑不到,问题是,旧连接 seg 进入新连接的概率比 16bit 摘要碰撞的概率更大吗,连续两次旧连接 seg 侵入新连接的平均时间比连续两次 16bit 摘要碰撞的时间更短吗?
不管怎样,真发生了怎么办,如何甄别?应用层校验啊。
设计一个绝对可靠的传输协议初衷是好的,但如果为保证绝对可靠而引入概率很低但复杂的机制使代码膨胀,就是坏的。综合来看,协议的可靠性是收益,而 cpu,内存的时空成本,人员维护成本都是开销。
保证交通工具 99.99% 的可靠性,剩下的交给保险公司,否则就要在飞机上挂巨型降落伞并防止降落伞故障而在地面铺巨型气垫了。
再来看保序。
保序指结果而不是过程,是目标管理,应该用内存拷贝(memcpy)而不是队列(queuing)的过程理解传输协议。
如果你有 100 个 cpu(就不扯 gpu 了),要把 10GB 的内存从一处拷贝到另一处,你会怎么做。这是一个非常经典的 “在规定时间内到某地集合” 的问题,逾期未到者会被催促,或干脆就不等了。因此,传输协议应交互的控制信息类似内存 bitmap(增量交互 or 差分交互,whatever) 而不是一个连续序列号空间(tcp scoreboard)。
要传输 10GB 数据,有 100 条路径可达目的地,协议应该可在这 100 条路径上随意喷洒 byte,效果是,对面的内存 bitmap 越来越密集,最终全部变成 1。而不是像 tcp 那样同时只能沿着其中一条路径传输 byte stream,然后发现这样效率很低后搞什么 mptcp,无非是缩小了问题而没有改变问题。
传输层属于端到端视角,不该看到 queuing,网络层的路由和转发才关注 queuing,传输协议要面向接口而不是面向实现。就像 memcpy,无论正着拷贝,反着拷贝,分若干块多个 cpu 一起拷贝均 ok,传输协议不必关注 byte 具体在哪条路径上传输,至于 byte stream 语义,就看你如何管理 buffer 以及如何交互 bitmap,这些反而是小事。
tcp 保序不松弛的原因在于它内置了 byte stream 语义,对 byte 间的相对位置就有了假设,如果假设先 x 后 y,则一旦先收到 y 而不是 x,就一定要做出 “修正逻辑”,对 tcp 而言,这就是 update scoreboard & mark lost & update reordering 那一块巨复杂的根源,等等,什么是 reordering,你看这就是过程管理而不是目标管理了吧。
再看拥塞控制。
传统意义上狭义的拥塞控制就是 tcp 拥塞控制,它本质上是在控制 inflight,比如通过控制 cwnd 将 inflight 限制在合理范围内,通过 pacing 减缓突发,显然控制的是报文数量是标量。然而 tcp 将这标量绑在 scoreboard 上,这意味着必须在 scoreboard 这个连续序列号空间把标量一个个数出来,但重传报文重传一次后就不能识别乱序,控制 inflight 的标量还没数完可能 scoreboard 就失效了,于是被迫跌入 rto retrans。后来 rack 为 scoreboard 上的报文贴上了时间戳,才能在时间维度区分同一个报文的多次传输,当然,rack 也并非只用于 tcp。
将一个标量绑在 scoreboard 序列号空间有个最大的问题现在才提,这种耦合事实上自己断送了拥塞控制的另一条路,除了控制 inflight 外,还可以换另一条路或多路径负载均衡,而 tcp 一旦这样做就必然会打乱 scoreboard 上报文相对顺序假设,造成 sender 采用更多 “修正逻辑”,后果就是大量乱序导致的不必要重传,甚至假 rto。
若采用 bitmap 交互应答确认,拥塞控制就能彻底独立出来。receiver 只需在应答中用特定字段标识收到的报文数量,标量的事直接用标量表示,sender 自然可以直接算出 inflight,从 bitmap 中选出下一批报文填充 inflight 维持守恒律即可。
端到端拥塞控制的本质从不是什么端到端的 qos,而是用 inflight 适配网络管道,管道并不局限于单条路径,至于你是追求管道效能最高(E = bw / delay 最大),还是追求吞吐最高(bw 最大),或管道利用率最高(bw * min_delay 最大),以此来区分你使用哪种拥塞控制算法。
更有用的是,bitmap 而不是顺序序列号交互应答确认可以让协议更加柔性,receiver 可自行决定这次传输是可靠的还是允许有损的。
不针对 tcp,下图是一个传输协议的统一描述,可用于 quic,rdma 以及各种 rpc: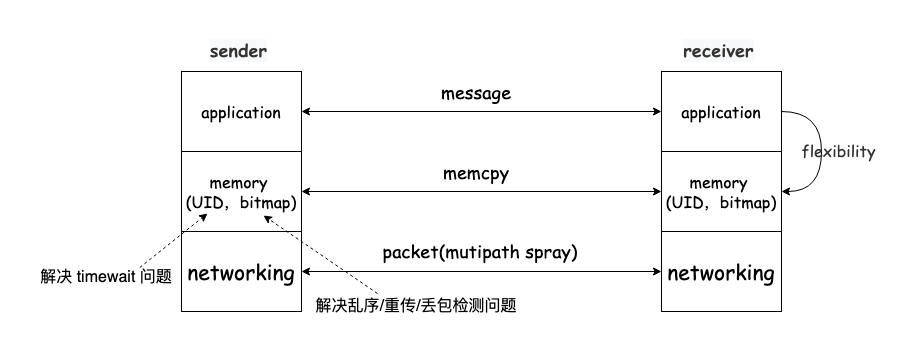
历史上,由于 buffer 小,带宽低,惜字如金多交互,时间换空间,tcp 等协议不得不如此设计,但悲哀的是这些历史遗留的传统理念却深深影响了几乎所有现代传输协议的设计和实现。
tcp 协议,无论从 rfc 规范,linux 实现还是日常运维,包含很多很贱很小概率很恶心的 issue,这些 issue 仅在两种场景下最有用,一个是面试,一个是业务咨询,并且如果你花了大量时间解决一个业务咨询后一般会将此问题用于面试,反过来也一样。大致可归为 “timewait 类”,“为什么乱序”,“为什么被 reset”,“窗口上不去” 几个恶心点,但这些问题大多不会严重影响业务,我本人被这类问题恶心了 18 年,期间曾做的一个 dcn transport 就是针对 tcp 的最大反驳,只有三千行代码,竟至少与三万行的 tcp 等效而无不及。本文借几个典型 issue 探讨一番。
浙江温州皮鞋湿,下雨进水不会胖。
以上就是关于大历史下的 tcp:一个松弛的传输协议相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!












