本文主要讲解关于【数据可视化-03】Pandas图形实战宝典相关内容,让我们来一起学习下吧!
【数据可视化-03】Pandas图形实战宝典
- 一、引言
-
- 1. 简述数据可视化的重要性
- 2. Pandas在数据处理和可视化中的作用
- 3. 本文将展示如何使用Pandas结合Matplotlib等库绘制各种图形
- 二、可视化图表
-
- 1. 折线图 :plot()
- 2. 条形图 :plot.bar()
- 3. 直方图:plot.hist()
- 4. 箱线图:plot.hist()
- 5. 面积图:plot.area()
- 6. 散点图:plot.scatter()
- 7. 六边形箱图:plot.hexbin()
- 8. 饼图:plot.pie()
- 9. 散点矩阵图:plotting.scatter_matrix()
- 10. 密度图:plot.kde()
- 三、自定义图形样式
-
- 1. 介绍如何自定义图形的颜色、线型、标签等
- 2. 示例代码:修改饼图的颜色,为折线图添加标题和轴标签
-
- 2.1 修改饼图颜色:
- 2.2 为折线图添加标题和轴标签:
- 四、图形保存与导出
-
- 1. 展示如何将绘制的图形保存为图片文件
- 2. 示例代码:保存为PNG、PDF等格式
- 五、总结与扩展
-
- 1. 总结Pandas在数据可视化中的应用
- 2. 提及其他数据可视化库
- 3. 鼓励读者进一步探索和实践
- 注意事项
- 参考文献
一、引言
1. 简述数据可视化的重要性
数据可视化是将数据以图形或图像的形式表示出来,使得复杂的数据更容易被人类理解和分析。在数据分析、商业智能、科学研究等领域,数据可视化都扮演着至关重要的角色。它不仅能够直观展示数据的分布、趋势和关联,还能帮助我们发现隐藏在数据中的模式和洞见,从而做出更明智的决策。
2. Pandas在数据处理和可视化中的作用
Pandas是一个强大的Python数据处理库,它提供了丰富的数据结构(如DataFrame和Series)和数据处理功能(如筛选、排序、分组等)。在处理完数据之后,Pandas还提供了与多种可视化库(如Matplotlib、Seaborn等)的集成接口,方便我们直接对数据进行可视化。Pandas的灵活性和易用性使其成为数据分析和可视化的重要工具。
3. 本文将展示如何使用Pandas结合Matplotlib等库绘制各种图形
在本文中,我们将通过实战案例来展示如何使用Pandas结合Matplotlib等库绘制各种图形。我们将从数据准备和加载开始,逐步介绍如何使用Pandas进行数据预处理和可视化设置,并最终通过代码展示如何绘制折线图、柱状图、饼图、直方图等多种图形。通过这些案例,读者将能够掌握Pandas在数据可视化中的基本应用,并能够在自己的工作中灵活运用。
具体的pandas可视化的案列代码参考pandas中文文档中的内容来实现,有需要的可以自行点击查看,下面将具体展示使用pandas可视化的来绘制一些常用图形的代码。
二、可视化图表
pandas数据可视化是在matplotlib的基础上进行封装的,所以在使用pandas进行数据可视化的时候需要导入matplotlib和pandas库和生成生成库numpy:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
1. 折线图 :plot()
在 Series 上,使用plot()方法绘制图形的代码如下:
ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
plt.show()
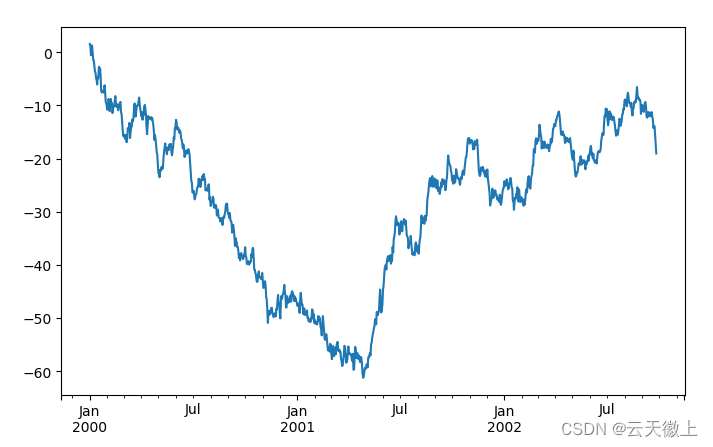
如果索引由日期组成,则调用gcf().autofmt_xdate()尝试按照上述方式很好地格式化 x 轴; 在 DataFrame 上,plot()方便使用标签绘制所有列代码如下:
df = pd.DataFrame(np.random.randn(1000, 4),
index=ts.index, columns=list('ABCD'))
df = df.cumsum()
plt.figure();
df.plot();
plt.show()
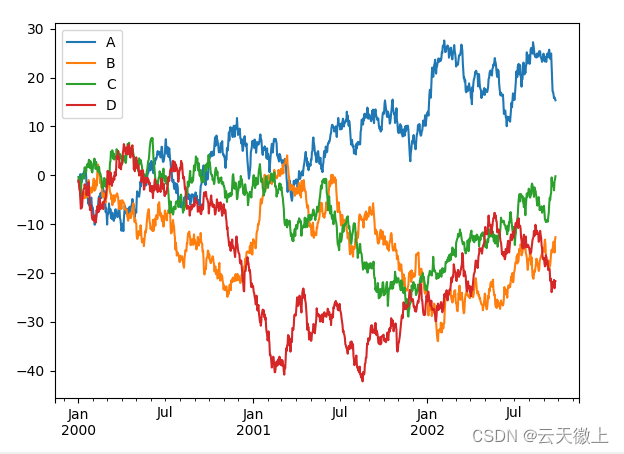
还可以使用 x 和 y 关键字将一列与另一列进行对比,生成对应的plot()图:
df3 = pd.DataFrame(np.random.randn(1000, 2), columns=['B', 'C']).cumsum()
df3['A'] = pd.Series(list(range(len(df))))
df3.plot(x='A', y='B')
plt.show()
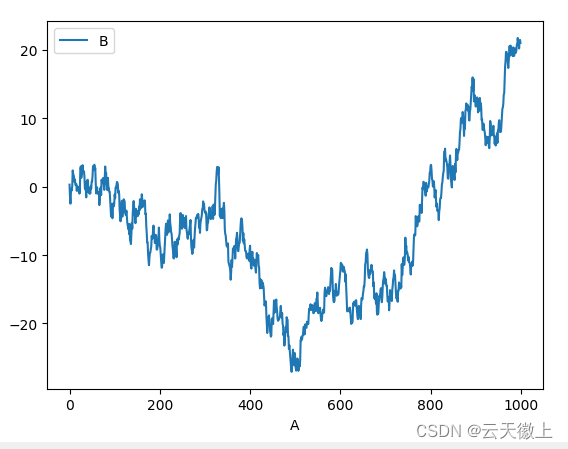
2. 条形图 :plot.bar()
对于带标签的非时间序列数据,可能希望生成条形图:
plt.figure();
df.iloc[5].plot.bar()
plt.show()
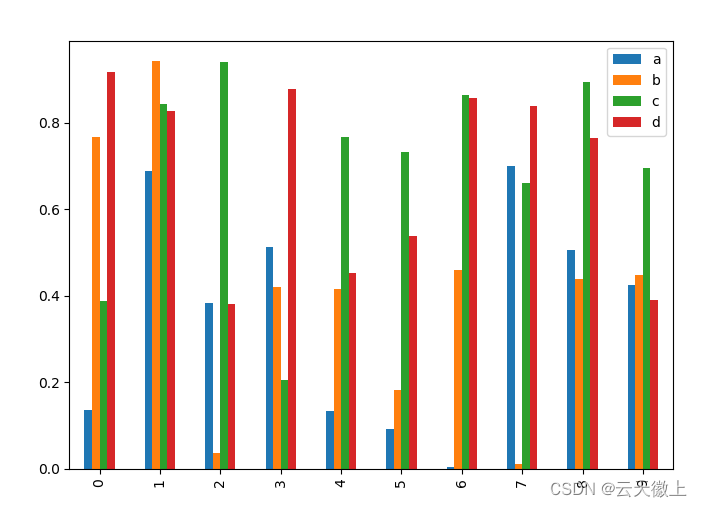
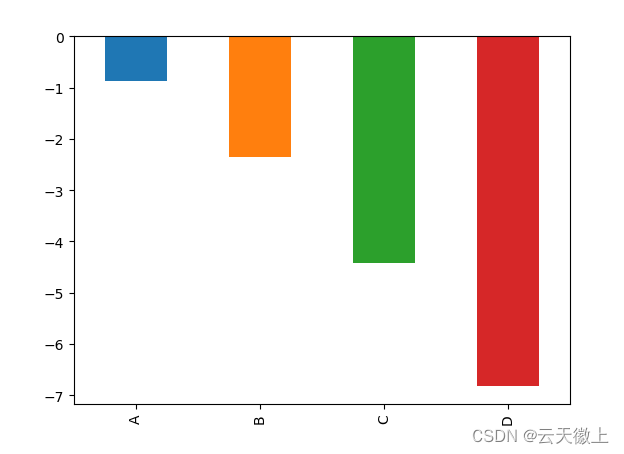 调用 DataFrame 的plot.bar()方法生成多条图:
调用 DataFrame 的plot.bar()方法生成多条图:
df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df2.plot.bar();
plt.show()
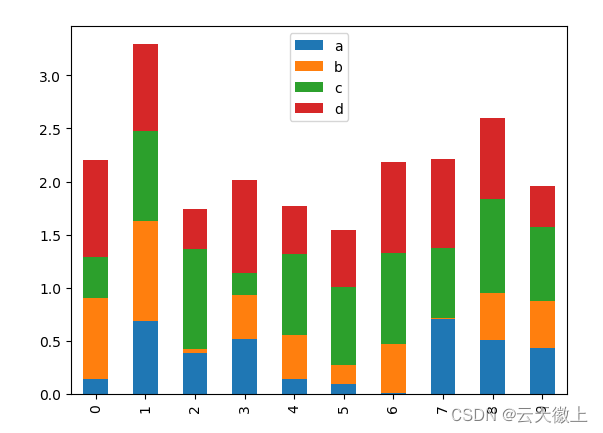
 要生成堆叠条形图,请传递:stacked=True
要生成堆叠条形图,请传递:stacked=True
df2.plot.bar(stacked=True);
plt.show()
3. 直方图:plot.hist()
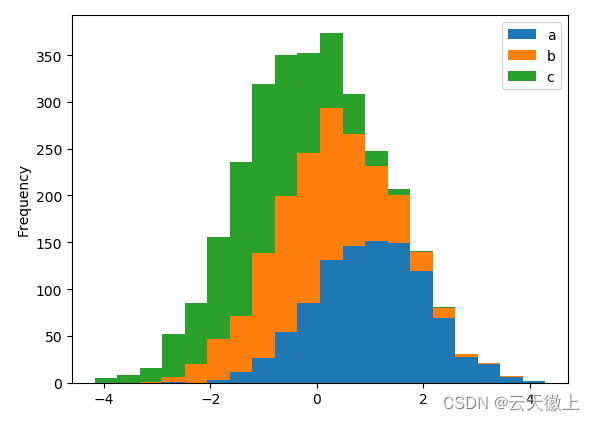
可以使用DataFrame.plot.hist()和Series.plot.hist()方法。
df4 = pd.DataFrame({'a': np.random.randn(1000) + 1,
'b':np.random.randn(1000),
'c': np.random.randn(1000) - 1},
columns=['a', 'b', 'c'])
plt.figure();
df4.plot.hist(alpha=0.5)

可以使用堆叠直方图。可以使用关键字更改箱大小。stacked=True 和设置bins的值
plt.figure();
df4.plot.hist(stacked=True, bins=20)
plt.show()
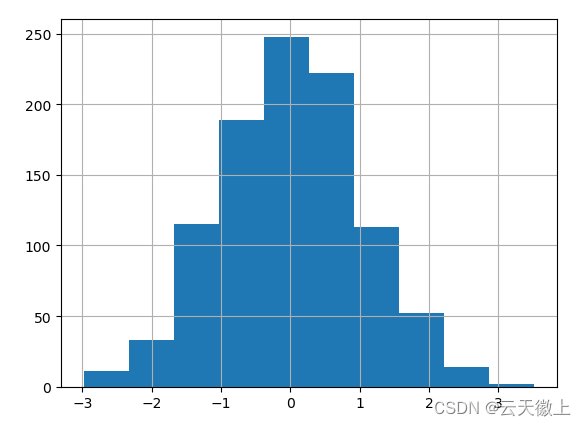
仍然可以使用现有的直方图绘制接口。DataFrame.hist
plt.figure();
df['A'].diff().hist()
plt.show()
 DataFrame.hist()在多个子图上绘制列的直方图:
DataFrame.hist()在多个子图上绘制列的直方图:
plt.figure()
df.diff().hist(color='k', alpha=0.5, bins=50)
plt.show()
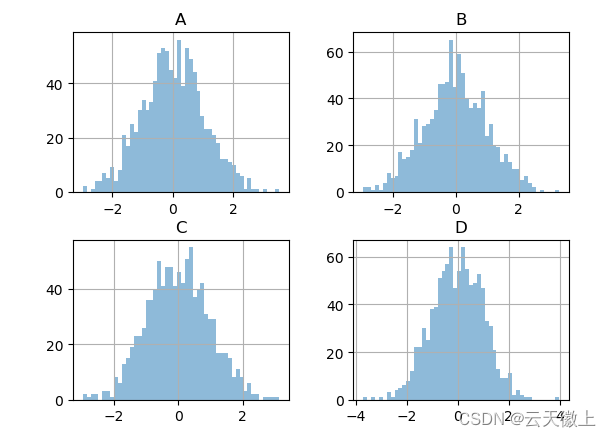
4. 箱线图:plot.hist()
绘制箱线图可以调用Series.plot.box()和DataFrame.plot.box()或DataFrame.boxplot()来实现,它可以可视化的展示每列中值的分布。
例如,下面是一个箱线图,表示对 [0,1] 上的统一随机变量的 10 个观测值的 5 次试验
df = pd.DataFrame(np.random.rand(10, 5), columns=['A', 'B', 'C', 'D', 'E'])
df.plot.box()
plt.show()
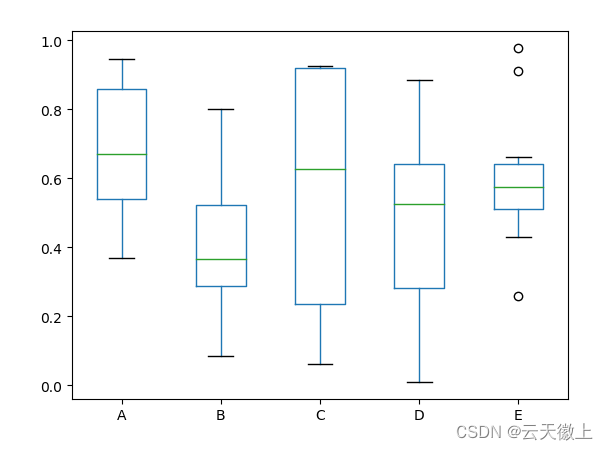 箱线图可以通过传递关键字来着色。可以通过设置color参数来实现,具体的可以查看下方的color字典,异常值的形式也可以通过sym参数来进行设置。
箱线图可以通过传递关键字来着色。可以通过设置color参数来实现,具体的可以查看下方的color字典,异常值的形式也可以通过sym参数来进行设置。
color = {'boxes': 'DarkGreen', 'whiskers': 'DarkOrange',
'medians': 'DarkBlue', 'caps': 'Gray'}
df.plot.box(color=color, sym='r+')
plt.show()

5. 面积图:plot.area()
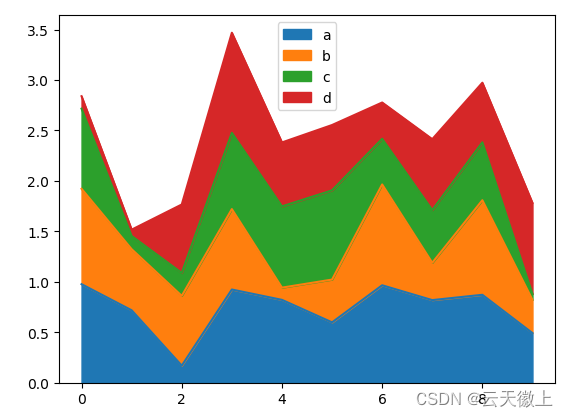
可以使用Series.plot.area()和DataFrame.plot.area()方法来创建面积图,默认情况下,面积图是堆叠的。若要生成堆积面积图,每列必须全部为正值或全部为负值。
当输入数据包含 NaN 时,它将自动填充 0。如果要按不同的值删除或填充,请使用 dataframe.dropna() dataframe.fillna()对空值和缺失值进行处理。
df = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df.plot.area();
plt.show()
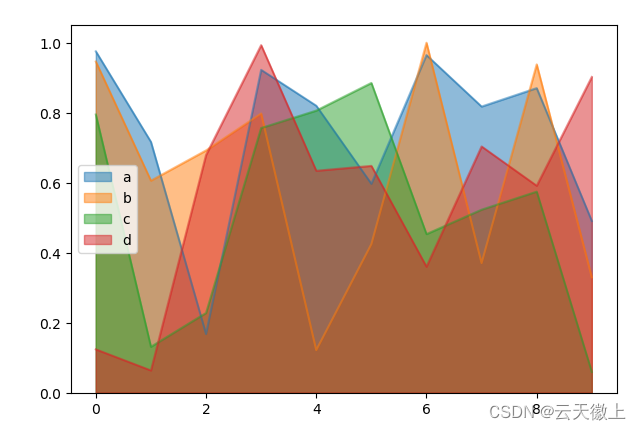
 当要生成未堆叠的图,请传递stacked=False 。除非另有说明,否则 Alpha 值设置为 0.5:
当要生成未堆叠的图,请传递stacked=False 。除非另有说明,否则 Alpha 值设置为 0.5:
df.plot.area(stacked=False);
plt.show()
6. 散点图:plot.scatter()
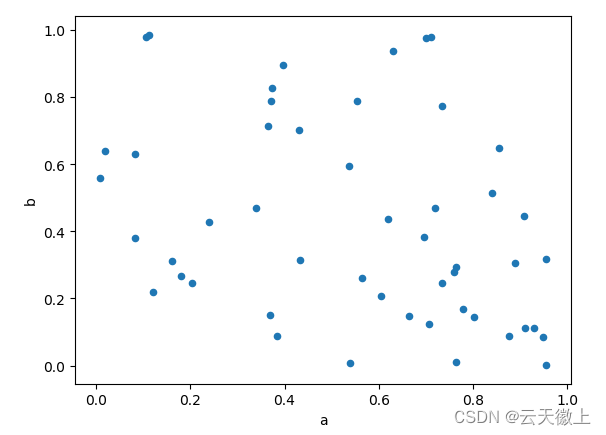
散点图可以使用DataFrame.plot.scatter()方法来绘制。散点图需要 x 轴和 y 轴的数值列。这些可以通过 和关键字指定。
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
df.plot.scatter(x='a', y='b');
plt.show()
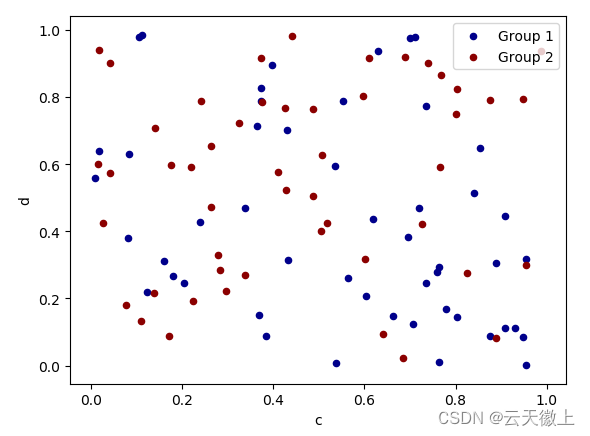
 要在单个轴上绘制多个列组,请重复指定目标的方法。建议指定和关键字来区分每个组。具体的代码如下:
要在单个轴上绘制多个列组,请重复指定目标的方法。建议指定和关键字来区分每个组。具体的代码如下:
ax = df.plot.scatter(x='a', y='b', color='DarkBlue', label='Group 1');
df.plot.scatter(x='c', y='d', color='DarkGreen', label='Group 2', ax=ax);
plt.show()
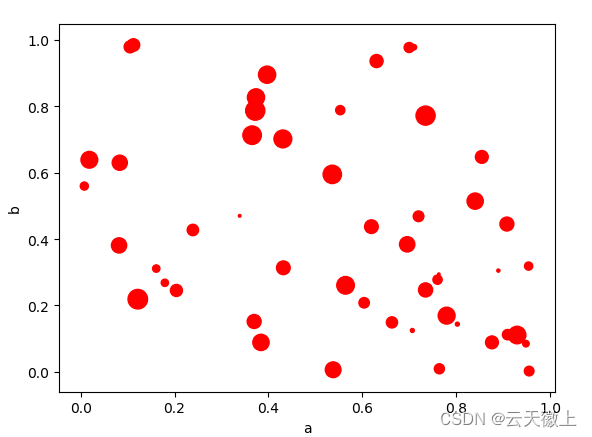
 可以传递 matplotlib 支持的其他关键字scatter.下面的示例显示了一个气泡图,其中一列作为气泡大小。
可以传递 matplotlib 支持的其他关键字scatter.下面的示例显示了一个气泡图,其中一列作为气泡大小。
df.plot.scatter(x='a', y='b', s=df['c'] * 200, color='Red');
plt.show()
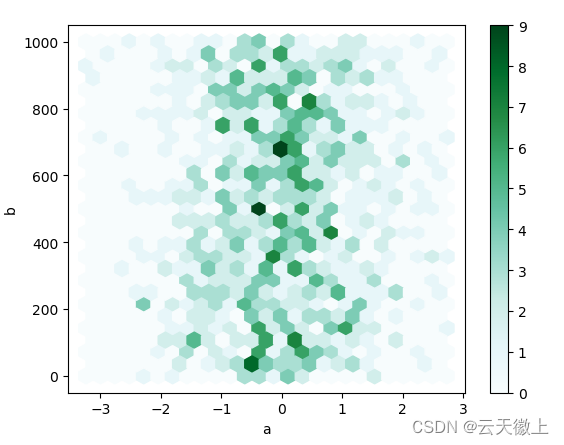
7. 六边形箱图:plot.hexbin()
可以使用以下方法创建六边形箱图DataFrame.plot.hexbin().如果数据过于密集而无法单独绘制每个点,则 Hexbin 图可以成为散点图的有用替代方法。
df = pd.DataFrame(np.random.randn(1000, 2), columns=['a', 'b'])
df['b'] = df['b'] + np.arange(1000)
df.plot.hexbin(x='a', y='b', gridsize=25)
plt.show()
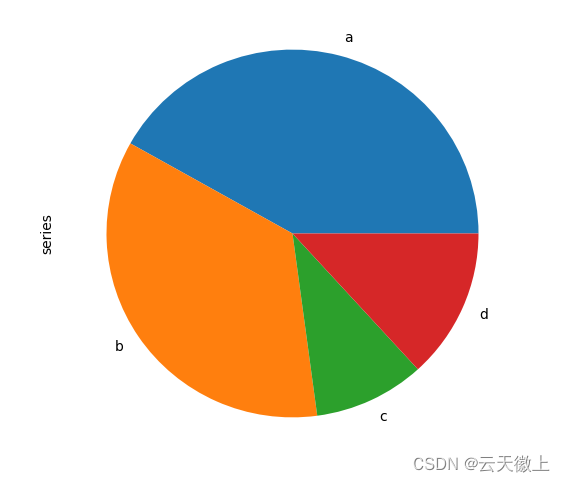
8. 饼图:plot.pie()
可以使用以下方法创建饼图,DataFrame.plot.pie()或Series.plot.pie().如果你的数据包含任何空值,它们将自动填充 0。如果数据中有任何负值,则将引发错误;
series = pd.Series(3 * np.random.rand(4),
index=['a', 'b', 'c', 'd'], name='series')
series.plot.pie(figsize=(6, 6))
plt.show()
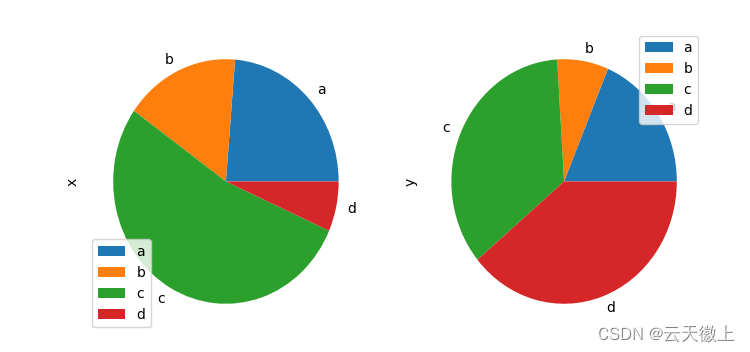
将dataframe中的多列绘制在一个图上;具体操作如下:
df = pd.DataFrame(3 * np.random.rand(4, 2),
index=['a', 'b', 'c', 'd'], columns=['x', 'y'])
df.plot.pie(subplots=True, figsize=(8, 4))
plt.show()
9. 散点矩阵图:plotting.scatter_matrix()
可以使用以下方法创建散点图矩阵:scatter_matrixpandas.plotting
from pandas.plotting import scatter_matrix
df = pd.DataFrame(np.random.randn(1000, 4), columns=['a', 'b', 'c', 'd'])
scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal='kde')
plt.show()

10. 密度图:plot.kde()
可以使用Series.plot.kde()和DataFrame.plot.kde()方法来绘制密度图。
ser = pd.Series(np.random.randn(1000))
ser.plot.kde()
plt.show()

三、自定义图形样式
1. 介绍如何自定义图形的颜色、线型、标签等
在数据可视化中,自定义图形样式是提升图表可读性和美观性的重要手段。Pandas通常结合Matplotlib库进行绘图,而Matplotlib提供了丰富的API来自定义图形的各种属性。以下是一些常见的自定义项:
-
颜色:可以通过设置
color参数来自定义线条、标记、区域等的颜色。 -
线型:可以通过设置
linestyle或ls参数来自定义线条的类型,如实线、虚线、点线等。 -
标签:可以通过设置
xlabel、ylabel和title参数来添加或修改坐标轴和标题的标签。
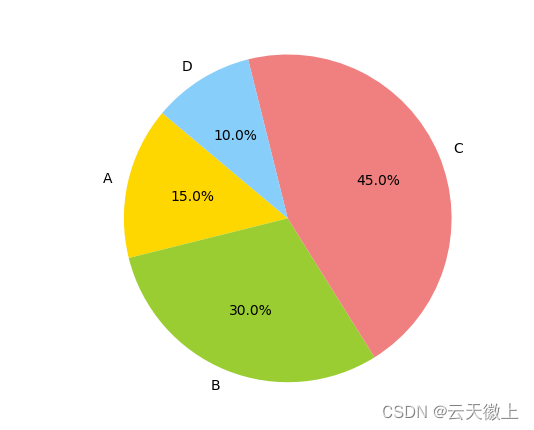
2. 示例代码:修改饼图的颜色,为折线图添加标题和轴标签
2.1 修改饼图颜色:
import matplotlib.pyplot as plt
import pandas as pd
# 假设我们有一个名为labels的列表和一个名为sizes的列表
labels = ['A', 'B', 'C', 'D']
sizes = [15, 30, 45, 10]
colors = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue'] # 自定义颜色
# 绘制饼图
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # 保证饼图是圆的
plt.show()
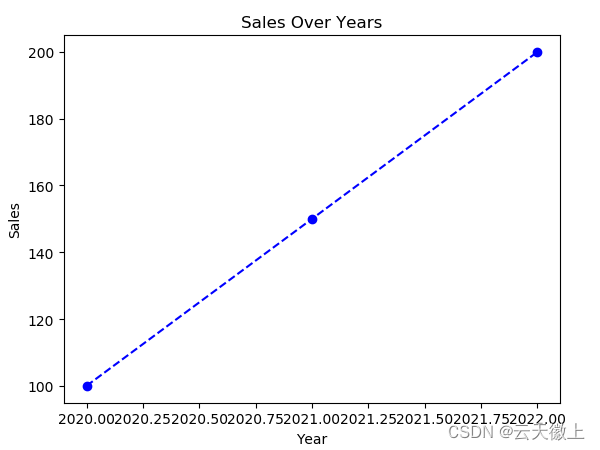
2.2 为折线图添加标题和轴标签:
import matplotlib.pyplot as plt
import pandas as pd
# 假设我们有一个DataFrame
data = {'Year': [2020, 2021, 2022], 'Sales': [100, 150, 200]}
df = pd.DataFrame(data)
# 绘制折线图
plt.plot(df['Year'], df['Sales'], marker='o', linestyle='--', color='blue') # 自定义线型和颜色
plt.title('Sales Over Years') # 添加标题
plt.xlabel('Year') # 添加x轴标签
plt.ylabel('Sales') # 添加y轴标签
plt.show()
四、图形保存与导出
1. 展示如何将绘制的图形保存为图片文件
在Matplotlib中,可以使用savefig()函数将绘制的图形保存为图片文件。该函数支持多种格式,如PNG、PDF、SVG等。
2. 示例代码:保存为PNG、PDF等格式
# 保存为PNG格式
plt.savefig('sales_plot.png', dpi=300) # dpi参数控制图片的分辨率
# 保存为PDF格式
plt.savefig('sales_plot.pdf', format='pdf')
# 显示图形(如果之前已经调用了plt.show(),则不需要再次调用)
plt.show()
五、总结与扩展
1. 总结Pandas在数据可视化中的应用
Pandas提供了强大的数据处理功能,结合Matplotlib等可视化库,可以方便地绘制各种图形,从而帮助我们更好地理解数据。Pandas的数据结构和数据处理功能为数据可视化提供了坚实的基础。
2. 提及其他数据可视化库
除了Matplotlib外,还有许多其他优秀的数据可视化库可以与Pandas结合使用,如Seaborn(提供了更高级的统计图形绘制功能)和Plotly(支持交互式图形和Web端部署)。这些库提供了更多样化、更美观的图形选项,值得进一步探索和学习。
3. 鼓励读者进一步探索和实践
数据可视化是一个广阔而有趣的领域,希望本文的内容能够激发你对数据可视化的兴趣。鼓励你进一步学习和实践Pandas和其他数据可视化库,探索更多可能性和创意。
注意事项
- 在编写博客时,每个部分的代码都是可运行的,并且附上必要的注释和解释。
- 对于复杂的图形绘制,可以拆分成多个步骤进行说明,以便读者更好地理解。
- 适当添加一些实际应用场景,增加文章的可读性和实用性。
参考文献
https://pypandas.cn/docs/user_guide/visualization.html#scatter-plot
以上就是关于【数据可视化-03】Pandas图形实战宝典相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!












