本文主要讲解关于数据挖掘实战-基于机器学习的垃圾邮件检测模型(文末送书)相关内容,让我们来一起学习下吧!

?♂️ 个人主页:@艾派森的个人主页
✍?作者简介:Python学习者 ? 希望大家多多支持,我们一起进步!? 如果文章对你有帮助的话, 欢迎评论 ?点赞?? 收藏 ?加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验步骤
4.1导入数据
4.2数据预处理
4.3数据可视化
4.4特征工程
4.5构建模型
4.6模型评估
文末推荐与福利
1.项目背景
随着互联网的普及和电子邮件的广泛使用,垃圾邮件的问题逐渐凸显。垃圾邮件不仅占据了用户的宝贵时间,还可能涉及到安全隐患,如恶意软件传播、网络钓鱼等。因此,有效地检测和过滤垃圾邮件成为了保障用户体验和网络安全的重要任务之一。
传统的垃圾邮件过滤方法通常采用规则引擎,通过事先定义一系列规则来识别垃圾邮件。然而,这种方法往往难以应对垃圾邮件攻击的多样性和不断变化的特征。为了提高垃圾邮件检测的准确性和适应性,近年来,研究者们逐渐将机器学习引入到垃圾邮件检测领域。
机器学习技术通过对大量邮件数据的学习,能够自动发现并利用隐藏在数据中的模式和特征。这为垃圾邮件检测提供了一种更加灵活和自适应的解决方案。在这一背景下,本实验旨在通过构建基于机器学习的垃圾邮件检测模型,提高垃圾邮件过滤的准确性和效率。
2.数据集介绍
数据集来源于Kaggle,原始数据集共有5572条,2个变量,具体含义解释如下:
Target:邮件的类型,'ham' or 'spam'。
Text:邮件的文本内容。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验步骤
4.1导入数据
导入第三方库并加载数据
# 导包
import warnings
import matplotlib.pyplot as plt
import missingno as msno
import seaborn as sns
import numpy as np
import pandas as pd
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from matplotlib.colors import ListedColormap
from sklearn import metrics
# 加载数据
df = pd.read_csv("spam_ham.csv",encoding='latin1')
df.head()
查看数据大小

查看数据基本信息

查看描述性统计
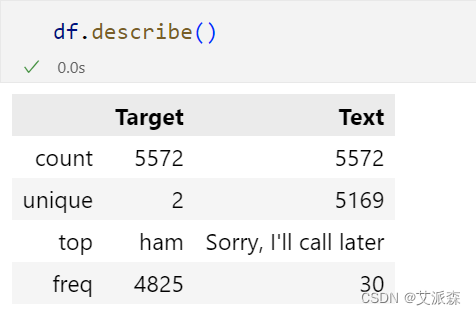
4.2数据预处理
统计缺失值

从结果来看,原始数据集不存在缺失值
检测是否存在重复值
删除重复值
4.3数据可视化
查看Target目标变量
# 检查目标列以便进一步分析
fig = sns.countplot(x=df['Target'])
fig.set_title('Count of Classes', fontsize=2, color='green')
fig.set_xlabel('Classes', fontsize=16, color='red')
fig.set_ylabel('Number of data', fontsize=16, color='red')
# 添加注释
for p in fig.patches:
fig.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=15, color='black', xytext=(0, 10),
textcoords='offset points')
plt.show()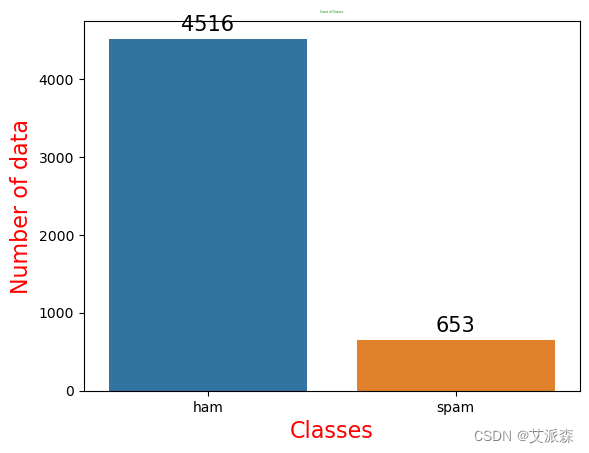
上面的计数图清楚地突出了数据的显著不平衡。
Text词云图
from wordcloud import WordCloud
text = ' '.join(df['Text'])
wordcloud = WordCloud(width=800, height=400, background_color='black').generate(text)
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud for Text Column')
plt.tight_layout()
plt.show()
4.4特征工程
为了追求全面的数据探索,我引入了新的功能:
No_of_Characters:表示文本消息中的字符数。
No_of_Words:表示文本消息中存在的字数。
No_of_Sentences:反映文本消息中句子的数量。
# 创建一个新的字符列计数
df['No_of_Character'] = df['Text'].apply(len)
df['No_of_Words'] = df.apply(lambda row: nltk.word_tokenize(row['Text']),axis=1).apply(len)
df['No_of_Sentences'] = df.apply(lambda row: nltk.sent_tokenize(row['Text']),axis=1).apply(len)
# 检查数据描述
df.describe().T
plt.figure(figsize=(15,12))
sns.pairplot(data=df,hue='Target')
plt.show()
在检查成对图时,很明显有一些异常值,都在“ham”类内。这很有趣,因为这些异常值可能传达了相同的信息,特别是短信的长度。在下一步中,我计划通过对这些异常值之一实施上限来解决这个问题,有效地处理它们的影响。
# 丢弃异常值
df = df[(df['No_of_Character']<350)]
df.shape
# 检查后
plt.figure(figsize=(15,12))
sns.pairplot(data=df, hue='Target')
plt.show()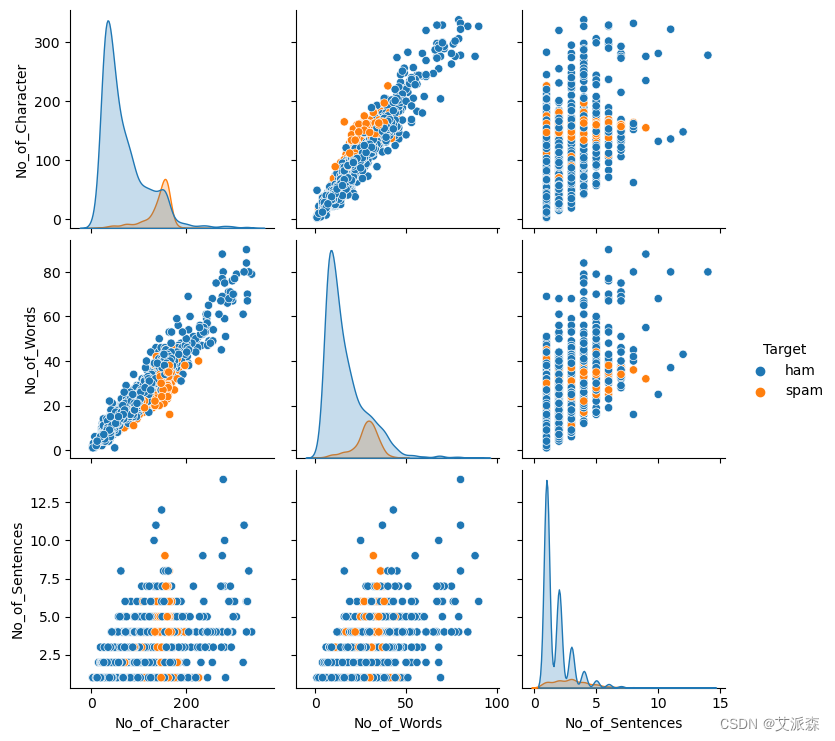
当然,有时重新访问和可视化数据不仅仅是为了发现新的东西,而是为了欣赏信息的美学。毕竟,谁能抗拒情节中那些充满活力和多样性的色彩的诱惑呢?
在NLP中,清理数据非常重要。对计算机来说,文本只是一堆符号,它不知道单词的意思。因此,为了帮助计算机更好地处理文本,我们必须让它更干净。
我们是这样做的:首先,我们只保留字母表中的字母。这意味着我们要去掉标点和数字。之后,我们把所有的字母都变成小写。清理后的文本将用于处理的下一个步骤。
# 让我在清洗之前检查一下样本文本
print("33[1mu001b[45;1m The First 5 Texts:33[0m",*df["Text"][:5], sep = "n")
# 创建一个函数来清理文本
def clean(Text):
sms = re.sub('[^a-zA-Z]',' ',Text) # 替换所有非字母
# 带空格的字符
sms = sms.lower()
sms = sms.split()
sms = ' '.join(sms)
return sms
df.loc[:,'Clean_text'] = df['Text'].apply(clean)
# 清洁后检查
print("33[1mu001b[45;1m The First 5 After Cleaning Texts:33[0m",*df["Clean_text"][:5], sep = "n")
分词就是将复杂的数据分解为更小的部分,称为标记(token)。这有点像把段落分成句子,然后把这些句子分成单独的单词。在这一步中,我特别将Clean_Text拆分为单词。这有助于我们更有效地分析和处理文本。
df.loc[:,'Tokenize_text'] = df.apply(lambda row: nltk.word_tokenize(row['Clean_text']),axis=1)
#标记文本后检查
print("33[1mu001b[45;1m The First 5 After Tokenize Texts:33[0m",*df["Tokenize_text"].loc[:5], sep = "n")
停用词(Stopwords)是指在语言中经常出现但不能给意思带来太多帮助的单词(比如few、is、an等)。虽然它们对句子的结构很重要,但它们在NLP的语言处理中没有多大价值。为了简化处理过程并删除不必要的重复,我将删除这些停用词。NLTK库提供了一组默认停词,我们将从文本中排除这些停词。
# 创建去除停用词函数
def remove_stopwords(text):
stop_word = set(stopwords.words('english'))
filtered_text = [word for word in text if word not in stop_word]
return filtered_text
df.loc[:,'Nostopword_text'] = df['Tokenize_text'].apply(remove_stopwords)
# 检查Nostopwords文本后的内容
print("33[1mu001b[45;1m The First 5 After Nostopword Texts:33[0m",*df["Nostopword_text"].loc[:5], sep = "n")
词干涉及到一个词的核心形式,通常被称为词根。去掉前缀或后缀后剩下的就是这个词根。这就像是回到了这个词的起源。语言随着时间的推移而变化,许多语言相互扩展。例如,英语起源于拉丁语。所以,当我们词干一个词,我们本质上是把它带回到它的基本形式。
另一方面,词源化也将一个词转换成它的词根形式。关键的区别在于确保这个词根在我们正在使用的语言中仍然有效,在我们的示例中是英语。选择词序化可以保证输出仍然是英语。
import spacy
# 加载英语语言模型
nlp = spacy.load("en_core_web_sm")
# 按词序排列单词表
def lemmatize_words(words):
doc = nlp(" ".join(words))
lemmas = [token.lemma_ for token in doc]
return lemmas
# 对"Nostopword_text"列应用排列规则
df.loc[:, "Lemmatized_Text"] = df["Nostopword_text"].apply(lemmatize_words)
# 打印按字母顺序排列的文本
print("33[1mu001b[45;1m The First 5 Texts after lemmatization:33[0m", *df["Lemmatized_Text"][:5], sep="n")
TF-IDF在NLP中表示Term Frequency - Inverse Document Frequency。在NLP中,我们需要将清理后的文本转换为数字,其中一种方法是将每个单词表示为矩阵。这个过程也被称为词嵌入或词矢量化。
以下是使用TfidfVectorizer()对数据进行矢量化的关键步骤:
创建语料库:这意味着收集一组按语料库排列的文本。
转换为向量形式:将语料库转换为数字向量格式。
标签编码:为“Target”列中的类分配数字标签。
注意:到目前为止,我们一直在数据中构建列以进行解释。
# 构建文本特征编码为矢量化形式的语料库
corpus = []
for i in df['Lemmatized_Text']:
msg = ' '.join([row for row in i])
corpus.append(msg)
corpus[:5]
print("33[1mu001b[45;1m The First 5 lines in corpus :33[0m",*corpus[:5], sep = "n")
# 将文本数据更改为数字
tfidf = TfidfVectorizer()
X = tfidf.fit_transform(corpus).toarray()
#Let's have a look at our feature
X.dtype
#标签编码目标并使用它作为y
label_encoder = LabelEncoder()
df.loc[:,"Target"] = label_encoder.fit_transform(df["Target"])4.5构建模型
步骤涉及模型建设
设置特点及目标:识别特征和目标变量,将它们分配给X和y。
分为测试集和训练集:将数据集分为训练集和测试集,以评估模型的性能。
训练模型:
使用训练数据拟合所有模型。
准确性交叉验证:
在训练集上使用交叉验证来评估模型,以确定其准确性。
#将标签和特征的值设置为y和X(我们已经在向量化中做了X…)
y = df['Target']
# 分割测试集和训练集
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2,random_state=45)from sklearn.preprocessing import LabelEncoder
# LabelEncoder将字符串标签转换为数值
label_encoder = LabelEncoder()
y_train_encoded = label_encoder.fit_transform(y_train)
# 对分类器进行测试
classifiers = [MultinomialNB(),
RandomForestClassifier(),
KNeighborsClassifier(),
SVC()]
for idx, cls in enumerate(classifiers):
cls.fit(X_train, y_train_encoded)
# 管道和模型类型的字典,便于参考
pipe_dict = {0: "NaiveBayes", 1: "RandomForest", 2: "KNeighbours", 3: "SVC"}# 交叉验证
for i, model in enumerate(classifiers):
cv_score = cross_val_score(model, X_train, y_train_encoded, scoring="accuracy", cv=10)
print("%s: %f " % (pipe_dict[i], cv_score.mean()))
4.6模型评估
# LabelEncoder将字符串标签转换为数值
label_encoder = LabelEncoder()
y_train_encoded = label_encoder.fit_transform(y_train)
y_test_encoded = label_encoder.transform(y_test) # transform for test labels
# 模型评价
# 创建各种分数的列表
precision = []
recall = []
f1_score = []
trainset_accuracy = []
testset_accuracy = []
for model in classifiers:
pred_train = model.predict(X_train)
pred_test = model.predict(X_test)
prec = metrics.precision_score(y_test_encoded, pred_test)
recal = metrics.recall_score(y_test_encoded, pred_test)
f1_s = metrics.f1_score(y_test_encoded, pred_test)
train_accuracy = model.score(X_train, y_train_encoded)
test_accuracy = model.score(X_test, y_test_encoded)
# 追加分数
precision.append(prec)
recall.append(recal)
f1_score.append(f1_s)
trainset_accuracy.append(train_accuracy)
testset_accuracy.append(test_accuracy)# 初始化列表的数据。
data = {'Precision':precision,
'Recall':recall,
'F1score':f1_score,
'Accuracy on Testset':testset_accuracy,
'Accuracy on Trainset':trainset_accuracy}
# 创建pandas数据框架。
Results = pd.DataFrame(data, index =["NaiveBayes", "RandomForest", "KNeighbours","SVC"])
cmap2 = ListedColormap(["#E2CCFF","green"])
Results.style.background_gradient(cmap=cmap2)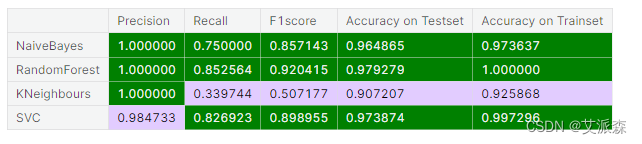
from sklearn.metrics import confusion_matrix
cmap = ListedColormap(["#E1F16B", "green"])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(15, 10))
for cls, ax in zip(classifiers, axes.flatten()):
y_pred = cls.predict(X_test)
y_test_arr = np.array(y_test, dtype=int)
y_pred_arr = np.array(y_pred, dtype=int)
cm = confusion_matrix(y_test_arr, y_pred_arr, labels=np.unique(y_test_arr))
sns.heatmap(cm, annot=True, fmt="d", cmap=cmap, ax=ax)
ax.set_title(type(cls).__name__)
ax.set_xlabel('Predicted')
ax.set_ylabel('True')
plt.tight_layout()
plt.show()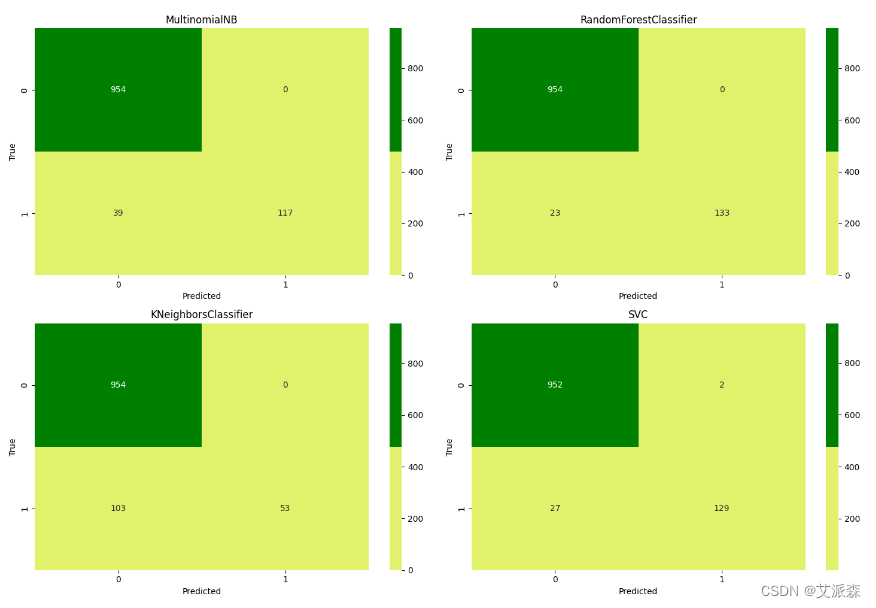
文末推荐与福利
《AI爆款文案 巧用AI大模型让文案变现插上翅膀》免费包邮送出3本!

内容简介:
掌握人工智能辅助文案写作的方式,就可以轻松写出高质量文案,进而快速实现文案变现。本书通过对10款人工智能应用的介绍及调试,帮助读者快速掌握人工智能辅助文案变现的方式。本书共10章,分别讲解AI智能创作,AI爆款文案写作工具,人工智能辅助泛流量文案、泛商业文案、私域文案创作,利用人工智能实现文案变现的底层逻辑,以及在今日头条、百家号、小红书、知乎等平台及不同展示形式下进行文案创作的实战案例等。
本书适合希望通过文案写作实现变现的写作新人、写作爱好者以及相关培训机构使用。
编辑推荐:
1. 爆款文案一键式创作:通过人工智能写爆款文案,提高效率的同时,也降低了试错成本的代价。本书通过大量的实际案例,展示了AI工具在文案创作中的应用和效果,使读者能够更直观地掌握AI工具的巨大优势。
2. 解构文案变现逻辑:文案变现的市场需求度极高,无论应用在新媒体文、短视频文案脚本还是知乎小红书种草文都能带来极高收益,而当文案变现与人工智能结合在一起时,一切就变得更有意思了。本书不仅关注文案创作本身,更着眼于如何利用AI工具实现文案的变现,帮助创作者实现商业价值的最大化。
3. 握未来之笔,引领文案革命新浪潮:本书不仅涉及泛流量文案、泛商业文案和私域文案的创作技巧,还针对主流平台和社交平台详细介绍了AI在文案创作实战中的高级技巧,引领文案变革新浪潮。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2024-4-13 20:00:00
京东:https://item.jd.com/14521488.html
当当:http://product.dangdang.com/29706300.html
名单公布时间:2024-4-13 21:00:00
资料获取,更多粉丝福利,关注下方公众号获取

以上就是关于数据挖掘实战-基于机器学习的垃圾邮件检测模型(文末送书)相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!












