本文主要讲解关于PyTorch深度学习实战(41)——循环神经网络与长短期记忆网络相关内容,让我们来一起学习下吧!
PyTorch深度学习实战(41)——循环神经网络与长短期记忆网络
-
- 0. 前言
- 1. 循环神经网络
-
- 1.1 传统文本处理方法的局限性
- 1.2 RNN 架构
- 2.3 RNN 内存机制
- 2. RNN 的局限性
- 3. 长短期记忆网络
-
- 3.1 LSTM 架构
- 3.2 构建 LSTM
- 小结
- 系列链接
0. 前言
循环神经网络 (Recurrent Neural Network, RNN) 和长短期记忆网络 (Long Short-Term Memory, LSTM) 是两种常见的处理序列数据的神经网络架构。RNN 是一种具有循环连接的神经网络,它在处理序列数据时能够考虑上下文信息,但当序列长度较长时,过去的信息难以正确传递到当前时间步。为了解决这一问题, LSTM 对 RNN 架构进行了改进,通过引入门控机制来有效地处理长期依赖关系。本节中,将介绍 RNN 及其变体 LSTM 的基本原理,并学习如何在 PyTorch 中进行构建。
1. 循环神经网络
神经网络可以通过多种方式进行构建,常见架构如下所示:
底部的紫色框代表输入,其后是隐藏层(中间的黄色框),顶部的粉色框是输出层。一对一的体系结构是典型的神经网络,在输入和输出层之间具有隐藏层。不同体系结构的示例如下:
| 架构 | 示例 |
|---|---|
| one-to-many | 输入是图像,输出是图像的预测类别概率 |
| many-to-one | 输入是电影评论,输出评论是好评或差评 |
| many-to-many | 将一种语言的句子使用神经网络翻译成另一种语言的句子 |
1.1 传统文本处理方法的局限性
循环神经网络 (Recurrent Neural Network, RNN) 是一种用于处理序列数据的神经网络,可以预测给定的事件序列中的下一个事件。一个简单的示例是,预测 This is an _____ 横线上的单词(假设横线上的目标单词为 example)。
(1) 传统的文本分析技术解决该问题的方式通常需要对每个单词进行编码,同时为潜在的新单词提供附加索引:
This: {1,0,0,0}
is: {0,1,0,0}
an: {0,0,1,0}
(2) 编码短语 This is an 为:
This is an: {1,1,1,0}
(3) 创建训练数据集:
Input --> {1,1,1,0}
Output --> {0,0,0,1}
(4) 最后,使用给定的输入和输出组合构建模型。
但该模型的主要缺点之一是当输入句子中的单词顺序改变时,输入表示并不会改变,例如,无论是 this is an,或者 an is this,它们的表示均为 {1, 1, 1, 0}。 但是,我们知道单词改变顺序后其含义并不同,因此不能用的相同形式表示,因此这需要我们使用不同的体系结构,句子中的每个单词都需要按照文本顺序输入到不同的输入框中,因此,句子的结构得以被保留。例如,this 输入第一个框中,is 输入第二个框中,an 输入第三个框中,输出框中将输出预测值,类似 many-to-one 架构。 了解 RNN 架构如何解决传统文本处理方法的缺陷后,在下一节中,我们继续介绍 RNN 架构的计算过程。
1.2 RNN 架构
可以将 RNN 视为一种内存保存机制,如果网络能够提供一个单独的内存变量,每次提取词向量的特征并刷新内存变量,直至最后一个输入完成,此时的内存变量即存储了所有序列的语义特征,并且由于输入序列之间的先后顺序,使得内存变量内容与序列顺序紧密关联。RNN 架构展开后可视化如下:
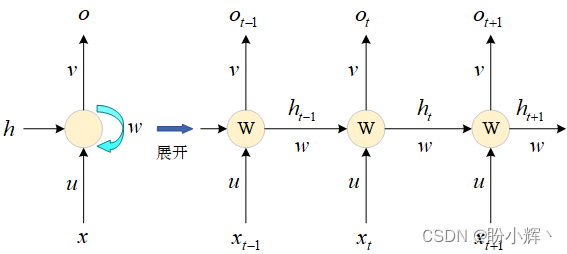
右侧的网络是左侧的网络的展开后的结果。右侧的网络在每个时刻接受当前时刻输入以及上一时刻网络状态,并在每个时刻提取一个输出。 在每个时刻
t
t
t,网络层接受当前时刻的输入
x
t
x_t
xt 和上一个时刻的网络状态向量
h
t
−
1
h_{t−1}
ht−1,根据网络内部运算逻辑
h
t
=
f
θ
(
h
t
−
1
,
x
t
)
h_t=f_{theta}(h_{t-1},x_t)
ht=fθ(ht−1,xt) 计算得到当前时刻的新状态向量
h
t
h_t
ht,并写入内存状态中。在每个时刻,网络层均有输出
o
t
o_t
ot,
o
t
=
g
Φ
(
t
)
o_t = g_{Phi}(t)
ot=gΦ(t),即根据网络的当前时刻状态向量计算后输出。 网络循环接受序列的每个特征向量
x
t
x_t
xt,并刷新内部状态向量
h
t
h_t
ht,同时形成输出
o
t
o_t
ot。这种网络结构就是循环神经网络 (Recurrent Neural Network, RNN) 结构。在上图中:
-
u
u
u 表示将输入层连接到隐藏层的权重
-
w
w
w 表示隐藏层到隐藏层的连接
-
v
v
v 表示隐藏层到输出层的连接
在循环神经网络中,当前时间步的输出不仅依赖于当前时间步的输入,还依赖于前一个时间步的隐藏层的值。通过将前一个时间步的隐藏层作为输入传入,同时考虑当前时间步的输入,我们可以获取前面各个时间步的信息。这样,我们就创建了一条连接管道,使得网络具有记忆存储的能力。
2.3 RNN 内存机制
如前一小节所示,我们需要内存存储器存储中间状态,在文本分析相关应用中,下一个单词不仅取决于前一个单词,而是取决于要预测的单词的完整上下文。 由于我们需要根据前面的单词预测下一个单词,因此需要一种方式将它们保留在内存中,以便我们可以更准确地预测下一个单词。此外,我们按单词出现的顺序存储内存;也就是说,与离预测单词较远的单词相比,最近出现的单词通常在预测时更有用。
2. RNN 的局限性
RNN 架构通过考虑多个时间步进行预测,可视化如下所示,随着时间的增加,早期输入的影响会逐渐降低:

更具体的,我们也可以通过公式得到相同的结论,例如我们需要计算第 5 个时刻网络的中间状态:
h
5
=
W
X
5
+
U
h
4
=
W
X
5
+
U
W
X
4
+
U
2
W
X
3
+
U
3
W
X
2
+
U
4
W
X
1
h_5 = WX_5 + Uh_4 = WX_5 + UWX_4 + U_2WX_3 + U_3WX_2 + U_4WX_1
h5=WX5+Uh4=WX5+UWX4+U2WX3+U3WX2+U4WX1
可以看到,随着时间的增加,如果
U
>
1
U>1
U>1,则网络中间状态的值高度依赖于
X
1
X_1
X1;而如果
U
<
1
U<1
U<1,则网络中间状态值对
X
1
X_1
X1 的依赖就少得多。对 U 矩阵的依赖性还可能在 U 值很小时导致梯度消失,而在 U 值很高时会导致梯度爆炸。 当在预测单词时存在长期依赖性时,RNN 的这种现象将导致无法学习长期依赖关系的问题。为了解决这个问题,我们将引入介绍长短期记忆 (Long Short Term Memory, LSTM) 体系结构。
3. 长短期记忆网络
在上一小节中,我们了解了 RNN 面临着梯度消失或爆炸的问题,导致它无法处理长期依赖问题。在本节中,我们将学习如何利用 LSTM 来解决这个问题。例如,假设输入句子如下:
I live in China. I speak ____.
在以上句子中,我们根据大多数来自中国的人都会说中文,而此人来自 China,可以推断出空白处应为 Chinese。在以上示例中,信号词 (China) 离空白值(试图预测的词)较近,但在现实场景中,信号词离空白值之间通常距离很远。当信号词与空白值之间的距离较大时,传统的 RNN 预测可能会因为梯度消失或梯度爆炸现象而出错,而使用 LSTM 可以解决这种情况。
3.1 LSTM 架构
在本节中,我们将学习 LSTM 如何克服 RNN 体系结构的长期依赖缺点,并构建一个简单示例,以便了解 LSTM 的各个组成部分。标准的 LSTM 架构示意图如下所示:

在上图中,可以看到,虽然输入
x
x
x 和输出
h
h
h 与 RNN 架构相似,但在 LSTM 中输入和输出之间的计算并不相同,网络在一个时间步内的计算过程如下所示:

在上图中,
x
x
x 和
h
h
h 表示输入层和 LSTM 的输出向量,内部状态向量 Memory 存储在单元状态
c
c
c 中,也就是说,相较于基础 RNN 而言,LSTM 将内部状态向量 Memory 和输出分开为两个变量,利用输入门 (Input Gate)、遗忘门 (Forget Gate)和输出门 (Output Gate) 三个门控来控制内部信息的流动。门控机制是一种控制网络中数据流通量的手段,可以较好地控制数据流通的流量程度。
3.1.1 遗忘门
需要忘记的内容是通过“遗忘门”获得的,用于控制上一个时间步的内存
c
t
−
1
c_{t-1}
ct−1 对当前时间步的影响,遗忘门的控制变量
f
t
f_t
ft 计算方式如下:
f
t
=
σ
(
W
x
f
x
(
t
)
+
W
h
f
h
(
t
−
1
)
+
b
f
)
f_t=sigma(W_{xf}x^{(t)}+W_{hf}h^{(t-1)}+b_f)
ft=σ(Wxfx(t)+Whfh(t−1)+bf)
sigmoid 激活函数使网络能够选择性地识别需要忘记的内容。在确定需要忘记的内容后,更新后的单元状态如下:
c
t
=
(
c
(
t
−
1
)
⊗
f
)
c_t=(c_{(t-1)}otimes f)
ct=(c(t−1)⊗f)
其中,
⊗
otimes
⊗ 表示逐元素乘法。例如,如果句子的输入序列是 I live in China. I speak ___,可以根据输入的单词 China 来填充空格,在之后,我们可能并不再需要有关国家名称的信息。我们根据当前时间步需要忘记的内容来更新单元状态。
3.1.2 输入门
输入门用于控制 LSTM 对输入的接受程度,根据当前时间步提供的输入将其他信息添加到单元状态中,通过 tanh 激活函数获得更新,因此也称为更新门。首先通过对当前时间步的输入和上一时间步的输出作非线性变换:
i
t
=
σ
(
W
x
i
x
(
t
)
+
W
h
i
h
(
t
−
1
)
+
b
i
)
i_t=sigma(W_{xi}x^{(t)}+W_{hi}h^{(t-1)}+b_i)
it=σ(Wxix(t)+Whih(t−1)+bi)
输入门中,输入更新计算方法如下:
g
t
=
t
a
n
h
(
W
x
g
x
(
t
)
+
W
h
g
h
(
t
−
1
)
+
b
g
)
g_t=tanh(W_{xg}x^{(t)}+W_{hg}h^{(t-1)}+b_g)
gt=tanh(Wxgx(t)+Whgh(t−1)+bg)
在当前时间步中需要忘记某些信息,并在其中添加一些其他信息,此时单元状态将按以下方式更新:
c
(
t
)
=
(
c
(
t
1
−
)
⊙
f
t
)
⊕
(
i
t
⊙
g
t
)
c^{(t)}=(c^{(t1-)}odot f_t)oplus(i_todot g_t)
c(t)=(c(t1−)⊙ft)⊕(it⊙gt)
得到的新的状态向量
c
(
t
)
c^{(t)}
c(t) 即为当前时间步的状态向量。
3.1.3 输入门
最后一个门称为输出门,我们需要指定输入组合和单元状态的哪一部分需要传递到下一个时刻,输入组合包括当前时间步的输入和前一时间步的输出值:
o
t
=
σ
(
W
x
o
x
(
t
)
+
W
h
o
h
(
t
−
1
)
+
b
o
)
o_t=sigma(W_{xo}x^{(t)}+W_{ho}h^{(t-1)}+b_o)
ot=σ(Wxox(t)+Whoh(t−1)+bo)
最终的网络状态值表示如下:
h
(
t
)
=
o
t
⊙
t
a
n
h
(
c
(
t
)
)
h^{(t)}=o_todot tanh(c^{(t)})
h(t)=ot⊙tanh(c(t))
这样,我们就可以利用 LSTM 中的各个门来有选择地识别需要存储在存储器中的信息,从而克服了 RNN 的局限性。
3.2 构建 LSTM
在文本相关的任务中,每个单词都是 LSTM 的一个输入(每个时间步一个单词)。为了使用 LSTM 架构,需要执行以下两个步骤:
- 将每个单词转换成一个嵌入向量
- 将与时间步对应的单词的嵌入向量作为输入传递给
LSTM
将输入单词转换为嵌入向量可以帮助网络更好地理解单词之间的语义关系,使用嵌入向量可以减少为每个单词创建一个 one-hot 编码向量所需的存储空间,并使模型更加高效。如果词汇表中有 10 万个不同的单词,我们必须在将它们传递到网络之前对它们进行热编码。但是,为每个单词创建一个独热编码向量会丢失单词的语义含义,例如,like 和 enjoy 具有相似的语义,应该具有相似的向量。为了解决这种情况,我们可以利用单词嵌入,语义相似的单词在嵌入空间上距离也会更近,单词嵌入的获取方式如下:
embed = nn.Embedding(vocab_size, embed_size)
在以上代码中,nn.Embedding 方法以 vocab_size 个维数作为输入,并返回 embed_size 维数作为输出。这样,如果词汇表大小为 100K,嵌入大小为 128,则每一个单词都表示为 128 维向量,一般而言,相似的单词将具有相似的嵌入。
接下来,通过 LSTM 传递单词嵌入。LSTM 在 PyTorch 中使用 nn.LSTM 方法实现:
hidden_state, cell_state = nn.LSTM(embed_size, hidden_size, num_layers)
在以上代码中,embed_size 表示每个时间步对应的嵌入大小,hidden_size 对应隐藏层输出的维度,num_layers 表示 LSTM 堆叠的次数,nn.LSTM 方法返回隐藏状态值和单元状态值。
小结
循环神经网络 (Recurrent Neural Network, RNN) 通过将前一个时间步的隐藏状态作为当前时间步的输入,实现对序列数据的建模,由于循环连接的存在,RNN 能够捕获时间依赖关系,然而,RNN 在处理长期依赖性问题时会遇到困难。为了解决这个问题,提出了 LSTM,通过引入门控机制改进 RNN 来有效地处理长期依赖关系。在本节中,了解了 LSTM 和 RNN 的基本原理,并介绍了如何在 PyTorch 中实现 LSTM。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解PyTorch深度学习实战(2)——PyTorch基础PyTorch深度学习实战(3)——使用PyTorch构建神经网络PyTorch深度学习实战(4)——常用激活函数和损失函数详解PyTorch深度学习实战(5)——计算机视觉基础PyTorch深度学习实战(6)——神经网络性能优化技术PyTorch深度学习实战(7)——批大小对神经网络训练的影响PyTorch深度学习实战(8)——批归一化PyTorch深度学习实战(9)——学习率优化PyTorch深度学习实战(10)——过拟合及其解决方法PyTorch深度学习实战(11)——卷积神经网络PyTorch深度学习实战(12)——数据增强PyTorch深度学习实战(13)——可视化神经网络中间层输出PyTorch深度学习实战(14)——类激活图PyTorch深度学习实战(15)——迁移学习PyTorch深度学习实战(16)——面部关键点检测PyTorch深度学习实战(17)——多任务学习PyTorch深度学习实战(18)——目标检测基础PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测PyTorch深度学习实战(22)——从零开始实现YOLO目标检测PyTorch深度学习实战(23)——从零开始实现SSD目标检测PyTorch深度学习实战(24)——使用U-Net架构进行图像分割PyTorch深度学习实战(25)——从零开始实现Mask R-CNN实例分割PyTorch深度学习实战(26)——多对象实例分割PyTorch深度学习实战(27)——自编码器(Autoencoder)PyTorch深度学习实战(28)——卷积自编码器(Convolutional Autoencoder)PyTorch深度学习实战(29)——变分自编码器(Variational Autoencoder, VAE)PyTorch深度学习实战(30)——对抗攻击(Adversarial Attack)PyTorch深度学习实战(31)——神经风格迁移PyTorch深度学习实战(32)——DeepfakesPyTorch深度学习实战(33)——生成对抗网络(Generative Adversarial Network, GAN)PyTorch深度学习实战(34)——DCGAN详解与实现PyTorch深度学习实战(35)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)PyTorch深度学习实战(36)——Pix2Pix详解与实现PyTorch深度学习实战(37)——CycleGAN详解与实现PyTorch深度学习实战(38)——StyleGAN详解与实现PyTorch深度学习实战(39)——小样本学习(Few-shot Learning)PyTorch深度学习实战(40)——零样本学习(Zero-Shot Learning)
以上就是关于PyTorch深度学习实战(41)——循环神经网络与长短期记忆网络相关的全部内容,希望对你有帮助。欢迎持续关注程序员导航网,学习愉快哦!











